What makes people good at solving novel problems? In part, it’s having relevant knowledge. And in part, it’s being able to think flexibly to apply that knowledge. So intelligence isn't a scalar: there are at least two dimensions — often called crystallized intelligence and fluid intelligence.
This is also broadly true of AI. We can see the distinction between language models regurgitating facts and reasoning models tracing out implications. We can see the difference between the performance of AlphaGo’s policynet, and what it achieves with Monte Carlo tree search. And we can imagine this distinction even for superintelligent systems.
This is a conceptual discussion. But the motivation is pragmatic. If we have a better understanding of the high-level workings of intelligence, we can make better predictions about what is required for superhuman performance, or what the dynamics of an intelligence explosion might look like. And this could also help us in thinking about how AI systems should be governed — e.g. should we be giving more attention to questions of who controls the creation and distribution of new knowledge?
Crystallized intelligence vs fluid intelligence
For the purposes of this post, intelligence is the ability to process information in ways that are helpful for achieving goals. Intelligent systems typically have both some crystallized intelligence (a body of implicit or explicit knowledge relevant to the task) and some fluid intelligence (being able to think things through on the fly).
In humans, knowing your multiplication tables, knowing how to ride a bike, or playing bullet chess are all chiefly about crystallized intelligence. But proving novel theorems, designing a bicycle from first principles, or playing slower games of chess all depend more on fluid intelligence.
Of course even in these cases crystallized intelligence is an important ingredient for the ability to think things through — e.g. mathematicians are more likely to be able to prove novel theorems if they have a solid grasp of the existing concepts and theorems, rather than needing to rederive them each time. And since our thinking often depends on our lower-level concepts and heuristics, it’s difficult to give clean definitions separating them.
For AI systems, we can be a little more precise. But first we’ll make a couple of related definitions:
- Crystallized knowledge refers to data objects encoding information relevant to the task
- An important category here (and for some AI systems the only relevant category) is trained neural nets, which contain implicit knowledge about the structure of the data they were trained on
- However, this could also include datasets that might be accessed directly by an AI system during operation
- This is analogous to a book used by a human; books are in some sense artefacts of pure crystallized knowledge
- Capacity for thought refers to compute available to think things through, as well as the algorithms dictating how that compute will be spent
- The algorithms might simply specify making repeated inference calls to a trained neural net (cf. chain of thought); but could also permit more complex calculations or arrangements (e.g. Monte Carlo tree search)
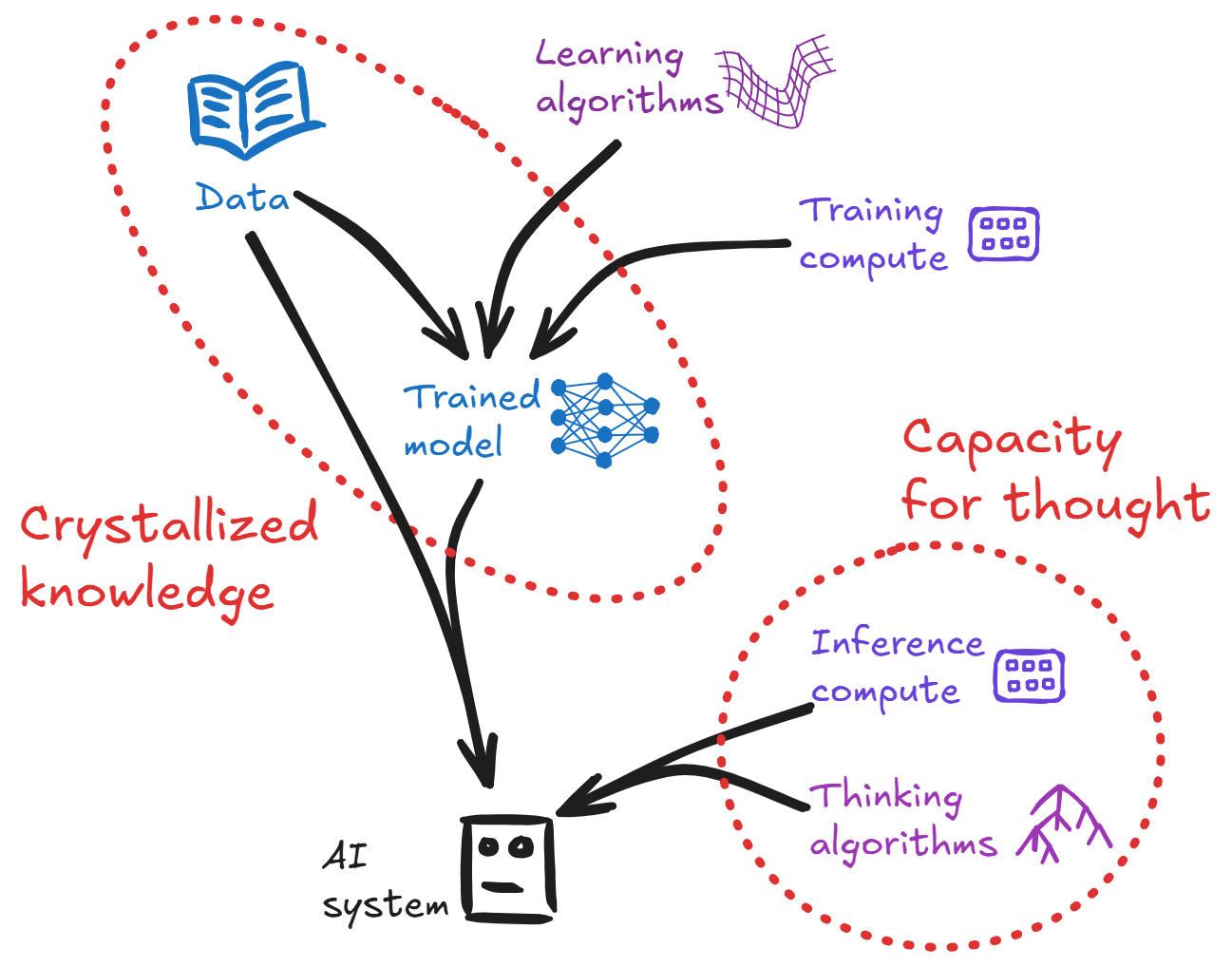
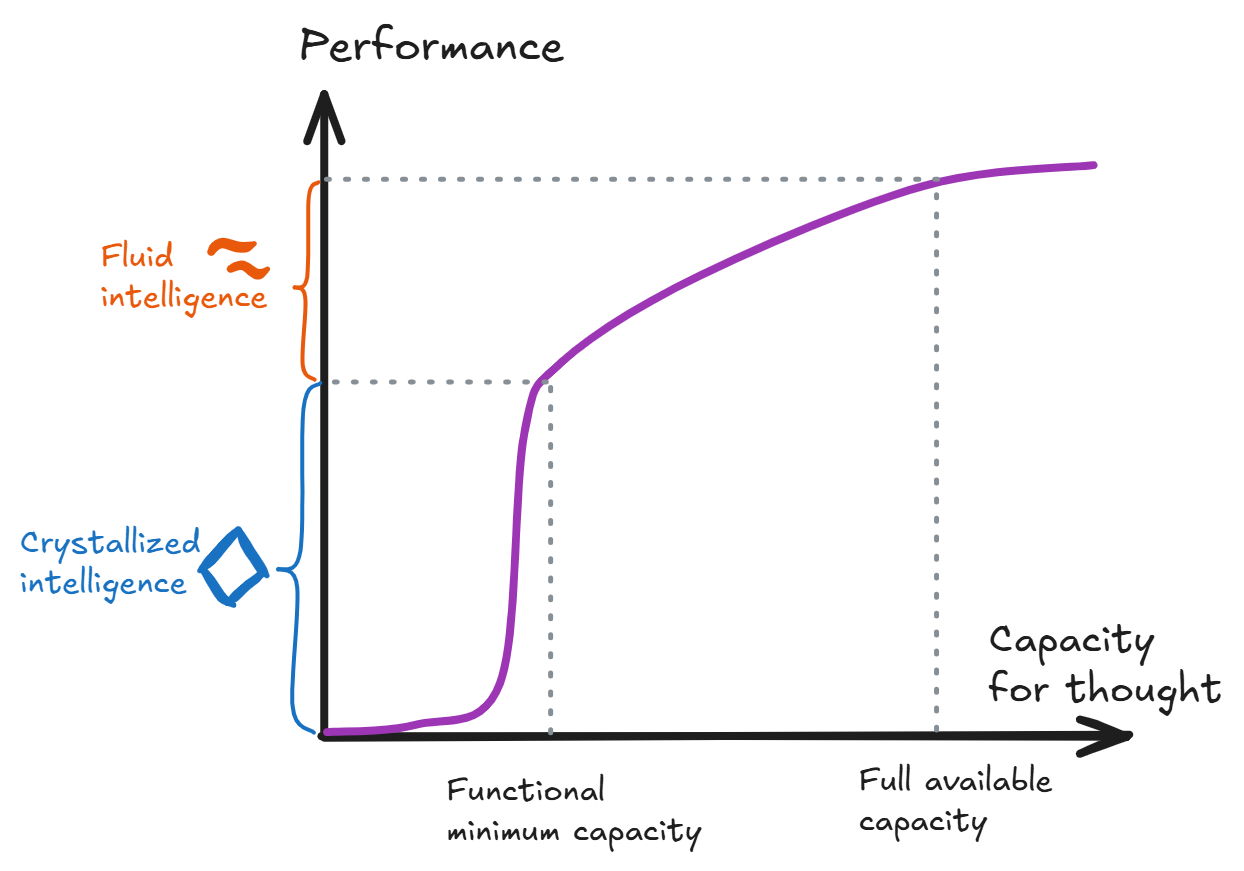
- Crystallized intelligence refers to the system performance obtainable with just a small amount of capacity for thought — e.g. making a single forward pass over a neural net, in order to extract the straightforward answer to the question at hand as suggested by the crystallized knowledge
- Fluid intelligence refers to the improvement in overall performance that is available by using the full capacity for thought (relative to the baseline established by crystallized intelligence)
The knowledge production loop
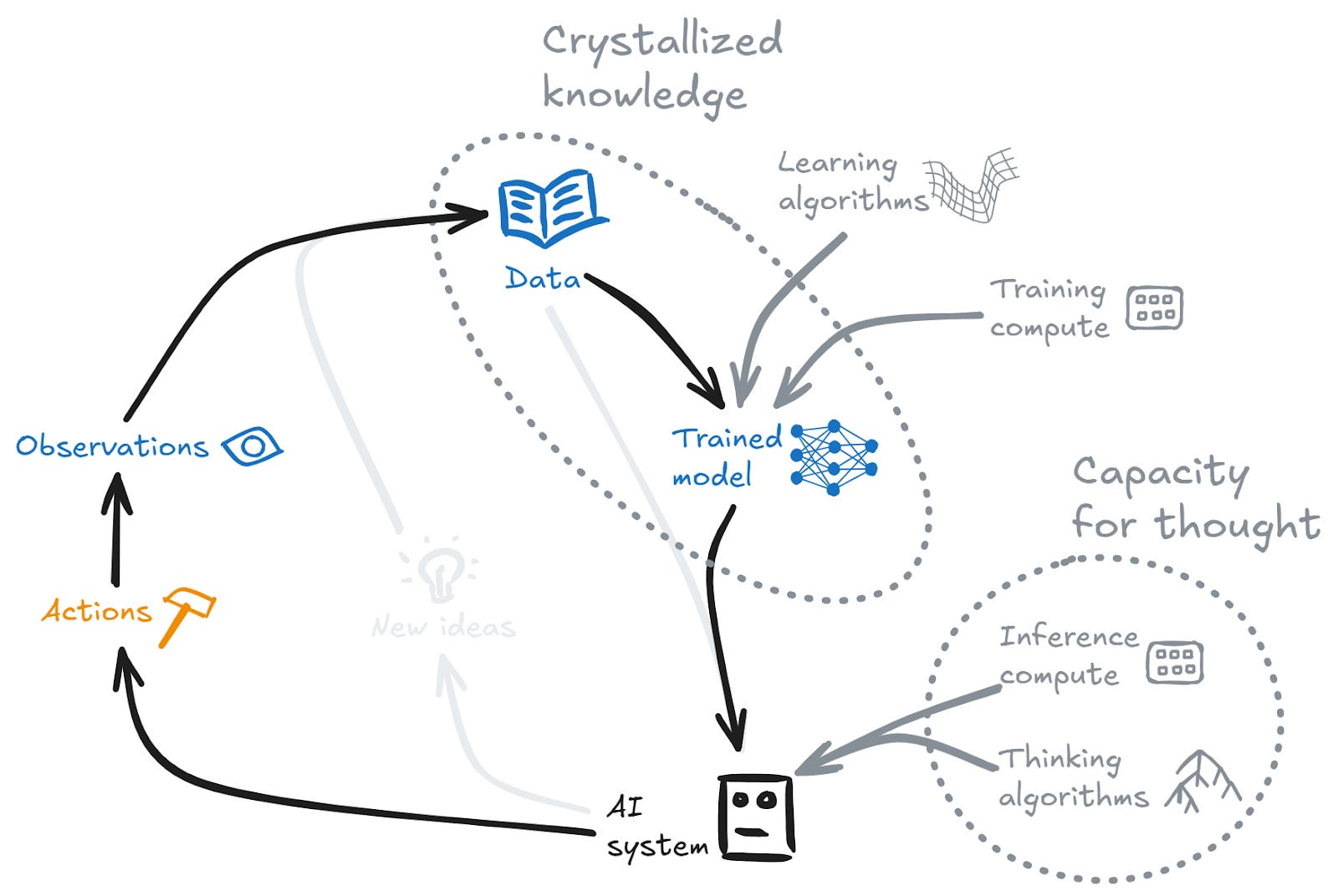
Crystallized intelligence depends crucially on knowledge. But where does the knowledge come from? Of course it may be exogenous to the system (e.g. LLMs functioning as crystallized intelligence based on human-produced data). But something interesting happens in cases where the system can produce its own new knowledge/data — via having new ideas, or via taking actions and observing the results. This gives rise to a loop where improved knowledge leads to stronger crystallized intelligence (and perhaps stronger fluid intelligence), which in turn can produce new higher-quality knowledge:
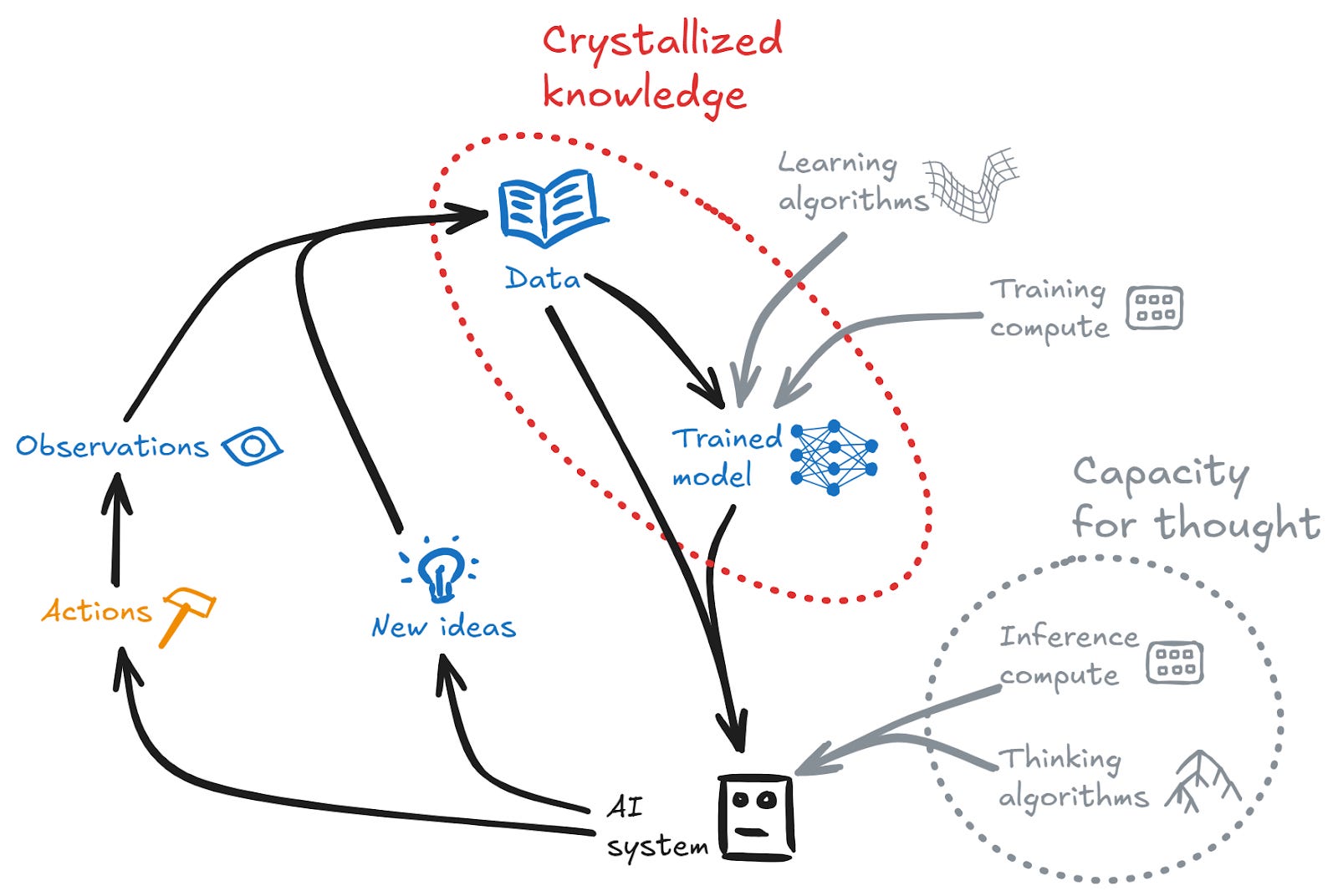
This is, in essence, a knowledge production engine. It isn’t a closed system — it requires compute to fuel the engine. But with sufficient fuel it may lead to large improvements in performance.
This is perhaps the simplest form of “recursive improvement” — subsequent iterations build on the improvement from earlier steps. And we’ve already seen cases where this kind of engine can produce significantly superhuman systems.
Crystallized intelligence and fluid intelligence in concrete systems
AlphaGo
The creation of the AlphaGo system has steps corresponding to a version of this loop:
- It starts with a database consisting of many expert human games
- The initial policy network and value network function as a form of crystallized knowledge — they provide useful information giving generalized approximations to what good play looks like
- Monte Carlo tree search is a form of thinking algorithm — it can be used to search for good moves (making use of inference compute to make calls to crystallized intelligence to help direct its search)
- It uses self-play to produce many decision-situations to analyse
- It considers and takes actions in these self-play games, and observes the output (i.e. which side wins)
- This creates many games (eventually with superhuman performance), which are added to the knowledge base
- This improves the policy network and value network in subsequent iterations — and hence the performance of the fluid intelligence
The successor system AlphaZero completes this same loop, but without the initial knowledge base — just the rules of the game (Go or Chess or Shogi) permitting it to make observations. Interestingly, although it builds up a suite of implicit concepts (overlapping with human concepts, but containing new ones), in contrast to the development of the human corpus of expertise, these concepts are purely implicit — they live only in the neural net representing crystallized intelligence, rather than explicit “new ideas” which live in the knowledge base.
Current LLMs
Current LLMs are borderline on completing the knowledge creation loop:
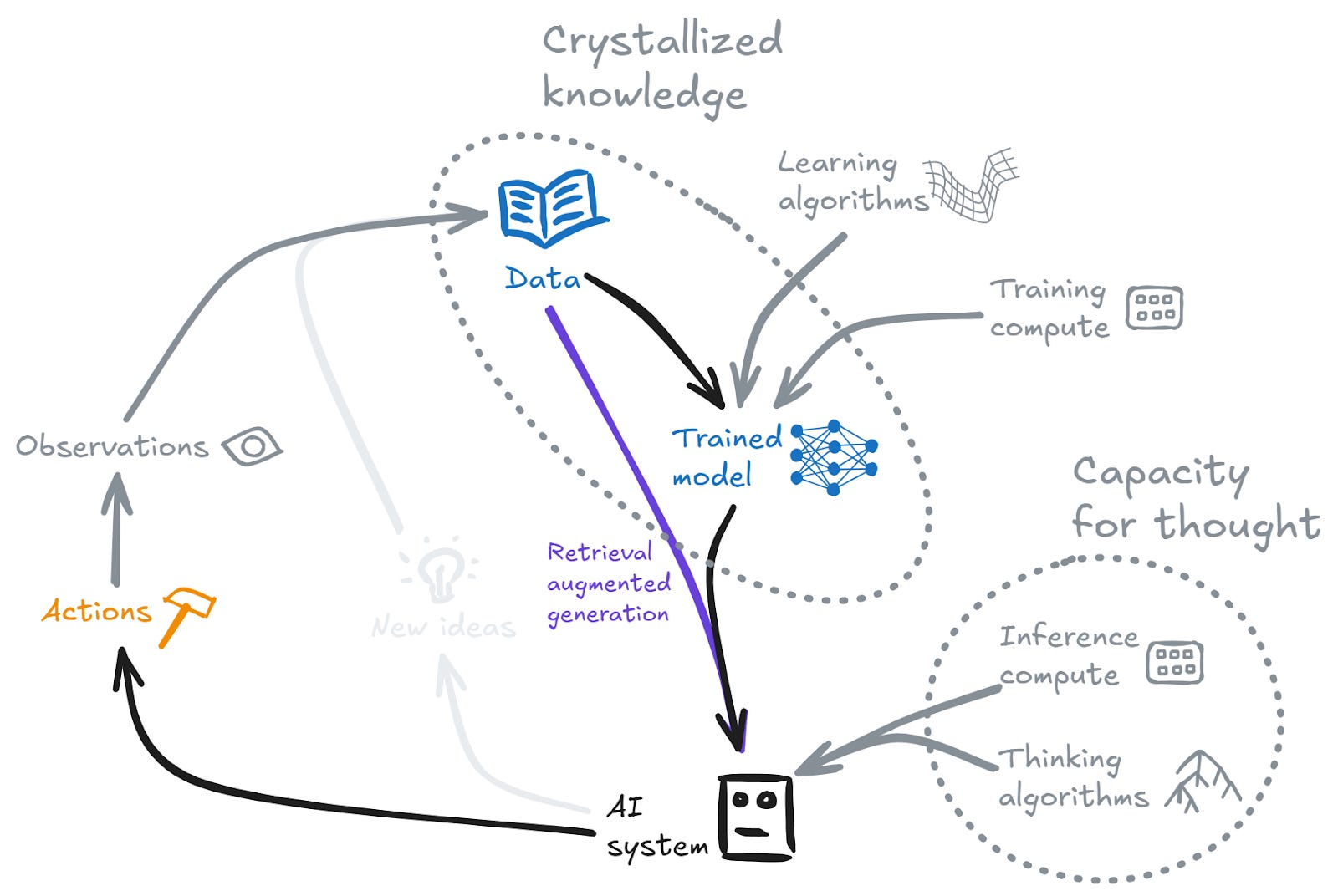
The LLMs of early 2025 are generally strong at crystallized intelligence. They have access to a lot of the data that human civilization has produced, including implicit knowledge about what best practices mean in many many situations.
LLMs are able to apply a certain amount of fluid intelligence, via chain of thought (or scaffolding). At the moment of writing, they’re not always very good at it, but they’re getting better fairly quickly — today’s reasoning models are much stronger than those of a year ago. Some of that strength flows from the kind of knowledge production loop marked:
- Processes like RLHF use the model to generate candidate answers, which human labellers can rank to provide data which teaches the model to behave a certain way.
- RLAIF automates this entirely, having the model rank its own answers
- Models can be used to create high-quality reasoning traces, which can then be fed back into them, or distilled into smaller models
On the other hand, LLMs aren’t yet at the edge of being able to produce new knowledge which is very helpful by the standards of human civilization. Compared to AlphaGo-like systems, this recursive loop appears to be hamstrung by the lack of clear feedback, and by the breadth of the search space. So it can only improve performance so far — for now.
The future
The distinction between crystallized and fluid intelligence is still meaningful for systems which are superhuman — here are some conceivable (but unrealistic) AI systems which pull out the distinctions:
- High crystallized intelligence
- Something like the top language models of today or a bit better in terms of fluid intelligence — but trained on a knowledge base which represents what civilization would know after a few hundred more years of progress at current levels
- Such a model knows much more about science, engineering, best practices … it would be like having access to the library of a more advanced civilization at our fingertips
- High fluid intelligence
- Whereas the top language models today are just reaching strong human performance on IQ tests, we can imagine systems which would blow such cognitive tests out of the water, doing better on a broad range of tests than any human, perhaps corresponding to an IQ of 300 (insofar as the scale remains meaningful that far out[1])
- However, we could have such a system which only had access to knowledge about the world that was available in say, the year 600 AD — so in many ways much lower crystallized intelligence than even today’s language models
- This system would be like a naive genius — not knowing any of the standard answers to things, but fantastic at riffing on ideas or thinking through complex multi-stage challenges
- This could be combined with:
- No learning — the system is essentially reset between sessions (just as LLMs today typically are); or
- Learning — the system can create internal memories and spend time trying to think things through, and put these back into its internal knowledge base, so that it uses the knowledge production loop to improve its crystallized intelligence with time
Crystallized knowledge will remain relevant
It is quite plausible that the basic knowledge production loop could give us transformative AI without any kind of strongly superhuman fluid intelligence. This would involve AI being leveraged to figure out many more things, at scale — the “country of geniuses in a datacentre” — and then the things that it figures out will be the new knowledge worth crystallizing.
Moreover, crystallized knowledge is likely to remain important even for strongly superintelligent systems. Even if you could figure everything out from first principles every time, it’s much less efficient than using cached knowledge [2]— similarly, the first transformative superintelligent systems almost certainly wouldn’t be meaningfully superintelligent if they did have to figure everything out each time.
The fluid intelligence enhancement loop
While the knowledge production loop may drive a large increase in knowledge (and hence crystallized intelligence), classical thinking about an intelligence explosion is more centrally about improvements to fluid intelligence. We might imagine something like this loop:
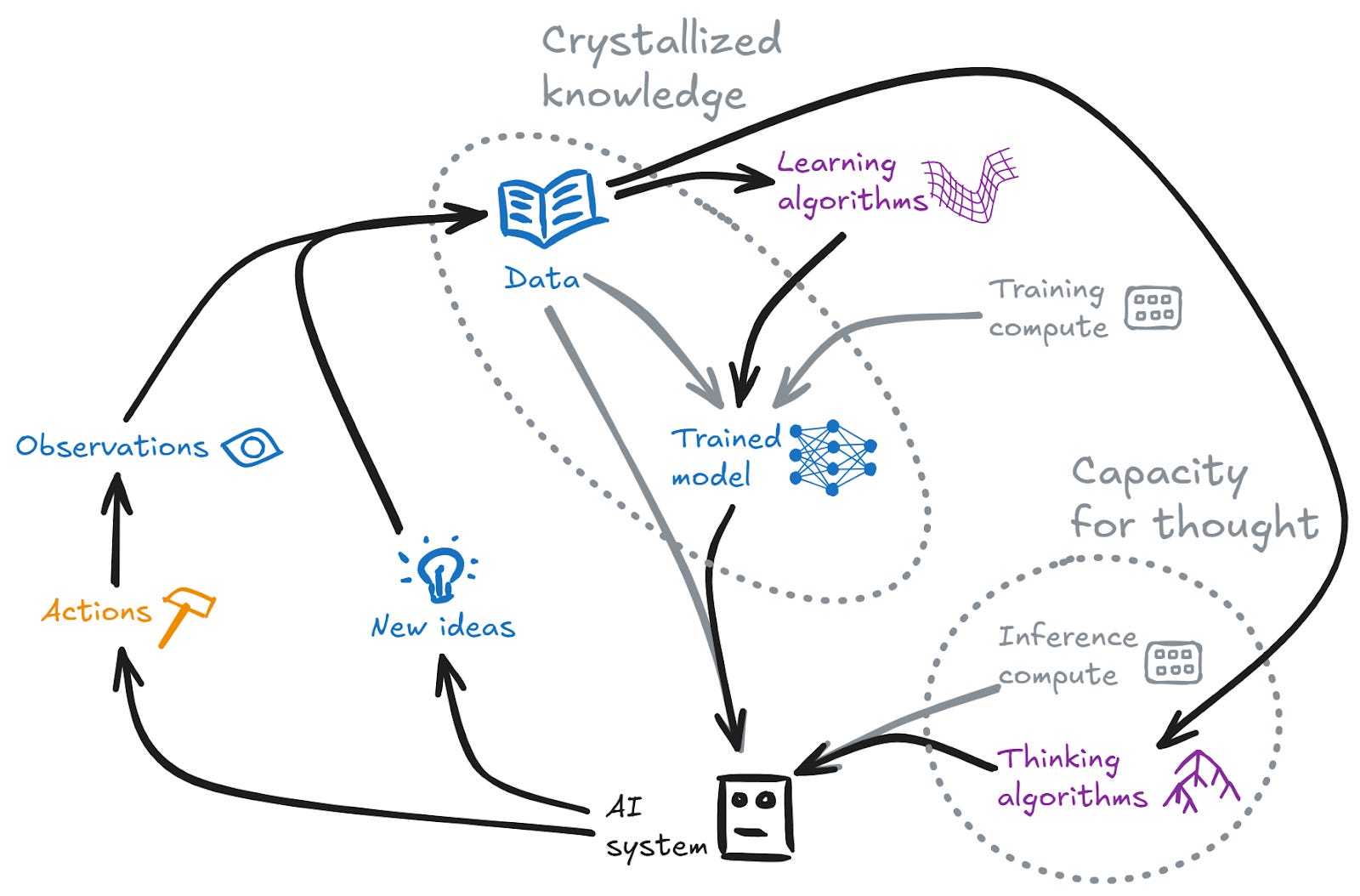
Even in this case, it seems likely that a lot of the improvements will be driven by the more traditional knowledge production loop — a system might iterate building new knowledge on top of new knowledge for many steps before it reaches an improvement to the algorithms that represents a fundamental upgrade to its fluid intelligence. But the possibility of this further type of upgrade increases the explosive potential of recursive improvement, compared to automated research without this possibility.
So what?
This post has been an exploration of conceptual foundations for thinking about intelligence, and the future of AI. Where can this take us? Ultimately I don’t know; I’m offering up the thinking in part in the hope that others may find useful applications beyond those I’ve considered. But here are some questions that I find my attention drawn towards:
- As systems get more powerful, can we make predictions about the relative ratios of compute that will be spent on:
- Inference?
- Training?
- Knowledge creation?
- For running the AI equivalents of research scientists?
- For running experiments?
- What will the dynamics of the intelligence explosion look like?
- How much will be captured by the basic knowledge production loop, and how much will factor through improvements to algorithms?
- Can splitting out these two components help us to sharpen our models of likely speed of takeoff?
- Note that these are both subcomponents of what has been called a software intelligence explosion, while a full-stack intelligence explosion would also involve improving hardware technology, and automating the entire technological base
- What does the space of superintelligent systems look like?
- In what circumstances is it plausible to have a system which is strongly superhuman in one domain without it being easy to create a system which is also superhuman in another domain?
- How might a misaligned power-seeking system seek to self-improve while keeping successor systems aligned to its own objectives?
- How will the knowledge created by automated research be stored?
- In broadly accessible papers or databases? In human-readable data tightly locked up in the vaults of top AI companies? Only in updates to the weights of cutting-edge models (a la AlphaGo)?
- Can we nudge this towards setups that more broadly empower people, by making the knowledge broadly available?
- How much does automated research require agents?
- Or how much can the key loops be just as efficient with e.g. non-agentic AI scientists?
- What can we do to facilitate differential progress?
- In thinking about how we might accelerate beneficial AI applications, I found it helpful to consider these different types of competence
- Can we use an understanding of the value of crystallized knowledge to inform our views of which paradigms may be safer or more valuable to pursue?
Thanks to Raymond Douglas, Lizka Vaintrob, Tom Davidson, Rudolf Laine, and Andreas Stuhlmüller for helpful comments, and to many more people for helpful conversations.
- ^
Perhaps it would be better to describe things in terms of some ELO-like score, which has a more natural crisp meaning; however that would require a choice of game, and I don’t in this context care enough to try to nail it down.
- ^
This point is not original; Beren makes a similar point about direct and amortized optimization in individual systems, and Rudolf Laine makes an analogous point about amortized optimization at the level of civilization.
In retrospect, it seems that LLM's were initially successful because they allowed engineers to produce certain capabilities in a way that almost maximally leaned on crystallized knowledge and minimally leaned on fluid intelligence.
It appears that LLM's have continued to be successful because we've gradually been able to get them to rely more on fluid intelligence.
(cross-posted on LW)
Love this!
As presaged in our verbal discussion my top conceptual complement would be to emphasise exploration/experimentation as central to the knowledge production loop - the cycle of 'developing good taste to plan better experiments to improve taste (and planning model)' is critical (indispensable?) to 'produce new knowledge which is very helpful by the standards of human civilization' (on any kind of meaningful timescale).
This because just flailing, or even just 'doing stuff', gets you some novelty of observations, but directedly seeking informative circumstances at the boundaries of the known (which includes making novel unpredictable events happen, as well as getting equipped with richer means to observe and record them, and perhaps preparing to deliberatively extract insight) turns out to be able to mine vastly more insight per resource (time, materials, etc.). Hence science, but also hence individual human and animal playfulness, curiosity, adversarial exercises and drills (self-play ish), and whatnot.
Said another way, maybe I'd characterise 'the way that fluid intelligence and crystallised intelligence synergise in the knowledge production loop' as 'directed exploration/experimentation'?
Having said that, I don't necessarily think these capacities need to reside 'in the same mind', just as contemporary human orgs get more of this done and more effectively than individuals. But the pieces do need to be fit to each other (like, a physicist with great physics taste can't usually very well complement a bio lab without first becoming a person with great bio taste).
Executive summary: The post argues that understanding the distinction between crystallized and fluid intelligence is key to analyzing the development and future trajectory of AI systems, including the potential dynamics of an intelligence explosion and how superintelligent systems might evolve and be governed.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.