Note: This post was crossposted from Planned Obsolescence by the Forum team, with the author's permission. The author may not see or respond to comments on this post.
Most experts were surprised by progress in language models in 2022 and 2023. There may be more surprises ahead, so experts should register their forecasts now about 2024 and 2025.
Kelsey Piper co-drafted this post. Thanks also to Isabel Juniewicz for research help.
If you read media coverage of ChatGPT — which called it ‘breathtaking’, ‘dazzling’, ‘astounding’ — you’d get the sense that large language models (LLMs) took the world completely by surprise. Is that impression accurate?
Actually, yes. There are a few different ways to attempt to measure the question “Were experts surprised by the pace of LLM progress?” but they broadly point to the same answer: ML researchers, superforecasters, and most others were all surprised by the progress in large language models in 2022 and 2023.
Competitions to forecast difficult ML benchmarks
ML benchmarks are sets of problems which can be objectively graded, allowing relatively precise comparison across different models. We have data from forecasting competitions done in 2021 and 2022 on two of the most comprehensive and difficult ML benchmarks: the MMLU benchmark and the MATH benchmark.
First, what are these benchmarks?
The MMLU dataset consists of multiple choice questions in a variety of subjects collected from sources like GRE practice tests and AP tests. It was intended to test subject matter knowledge in a wide variety of professional domains. MMLU questions are legitimately quite difficult: the average person would probably struggle to solve them.


At the time of its introduction in September 2020, most models only performed close to random chance on MMLU (~25%), while GPT-3 performed significantly better than chance at 44%. The benchmark was designed to be harder than any that had come before it, and the authors described their motivation as closing the gap between performance on benchmarks and “true language understanding”:
Natural Language Processing (NLP) models have achieved superhuman performance on a number of recently proposed benchmarks. However, these models are still well below human level performance for language understanding as a whole, suggesting a disconnect between our benchmarks and the actual capabilities of these models.
Meanwhile, the MATH dataset consists of free-response questions taken from math contests aimed at the best high school math students in the country. Most college-educated adults would get well under half of these problems right (the authors used computer science undergraduates as human subjects, and their performance ranged from 40% to 90%).

At the time of its introduction in January 2021, the best model achieved only about ~7% accuracy on MATH. The authors say:
We find that accuracy remains low even for the best models. Furthermore, unlike for most other text-based datasets, we find that accuracy is increasing very slowly with model size. If trends continue, then we will need algorithmic improvements, rather than just scale, to make substantial progress on MATH.
So, these are both hard benchmarks — the problems are difficult for humans, the best models got low performance when the benchmarks were introduced, and the authors seemed to imply it would take a while for performance to get really good.
In mid-2021, ML professor Jacob Steinhardt ran a contest with superforecasters at Hypermind to predict progress on MATH and MMLU. Superforecasters massively undershot reality in both cases.
They predicted that performance on MMLU would improve moderately from 44% in 2021 to 57% by June 2022. The actual performance was 68%, which superforecasters had rated incredibly unlikely.
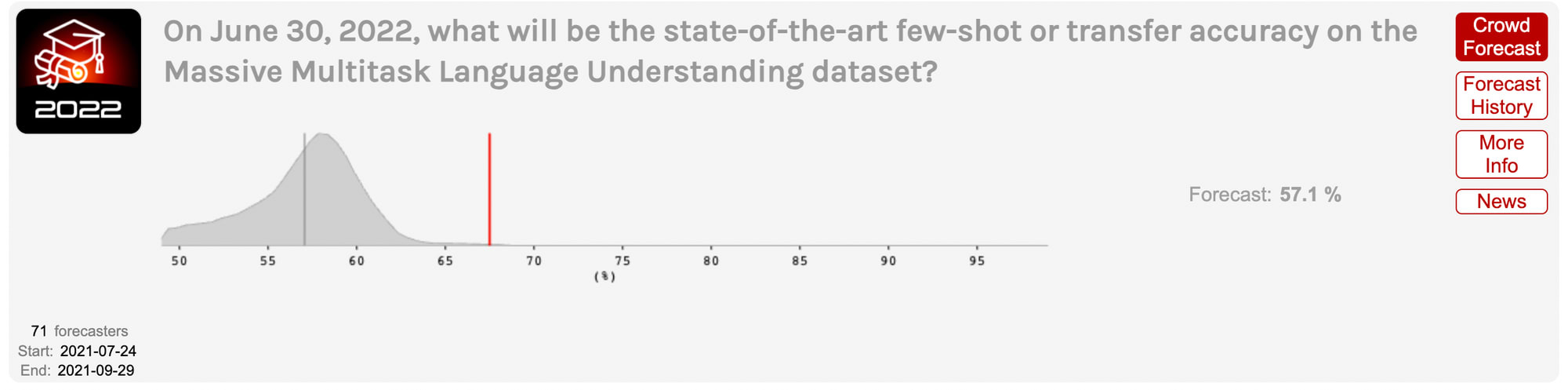
Shortly after that, models got even better — GPT-4 achieved 86.4% on this benchmark, close to the 89.8% that would be “expert-level” within each domain, corresponding to 95th percentile among human test takers within a given subtest.
Superforecasters missed even more dramatically on MATH. They predicted the best model in June 2022 would get ~13% accuracy, and thought it was extremely unlikely that any model would achieve >20% accuracy. In reality, the best model in June 2022 got 50% accuracy, performing much better than the majority of humans.
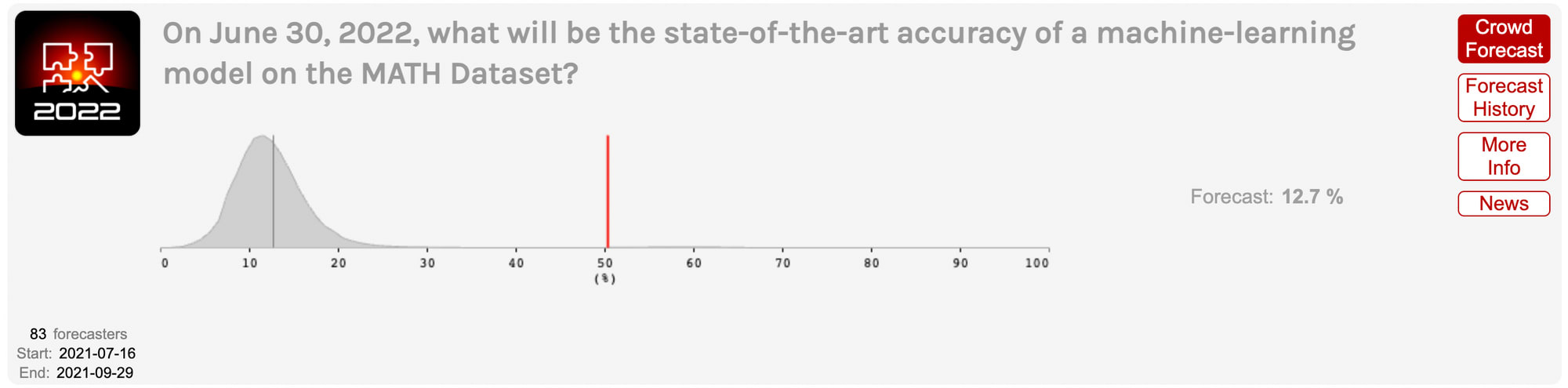
Did ML researchers do any better? Steinhardt himself did worse in 2021. In his initial blog post, Steinhardt remarked that the superforecasters’ predictions on MATH were more aggressive (predicting faster progress) than his own. We haven’t found any similar advance predictions from other ML researchers, but Steinhardt’s impression is that he himself anticipated faster progress than most of his colleagues did.
However, ML researchers do seem to be improving in their ability to anticipate progress on these benchmarks. In mid-2022, Steinhardt registered his predictions for MATH and MMLU performance in July 2023, and performed notably better: “For MATH, the true result was at my 41st percentile, while for MMLU it was at my 66th percentile.” Steinhardt also argues that ML researchers performed reasonably well on forecasting MATH and MMLU in the late-2022 Existential Risk Persuasion Tournament (XPT) (though superforecasters continued to underestimate benchmark progress).
Expert surveys about qualitative milestones
Not all forms of progress can be easily captured in quantifiable benchmarks. Often we care more about when AI systems will achieve more qualitative milestones: when will they translate as well as a fluent human? When will they beat the best humans at Starcraft? When will they prove novel mathematical theorems?
Katja Grace of AI Impacts asked ML experts to predict a wide variety of AI milestones, first in 2016 and then again in 2022.
In 2016, the ML experts were reasonably well-calibrated, but the predictions followed a clear pattern: progress in gameplay and robotics advanced slower than expected, but progress in language use (including programming) advanced more quickly than expected.
The second iteration of the survey was conducted in mid-2022, a few months before ChatGPT was released. This time accuracy was lower — experts failed to anticipate the progress that ChatGPT and GPT-4 would soon bring. These models achieved milestones like “Write an essay for a high school history class” (actually GPT-4 does pretty well in college classes too) or “Answer easily Googleable factual but open-ended questions better than an expert” just a few months after the survey was conducted, whereas the experts expected them to take years.
That means that even after the big 2022 benchmark surprises, experts were still in some cases strikingly conservative about anticipated progress, and undershooting the real situation.
Anecdata of researcher impressions
ML researchers rarely register predictions, so AI Impacts’ surveys are the best systematic evidence we have about what ML researchers expected ahead of time about qualitative milestones. Anecdotally though, a number of ML experts have expressed that they (and the ML community broadly) were surprised by ChatGPT and GPT-4.
For a long time, famous cognitive scientist Douglas Hofstadter was among those predicting slow progress. “I felt it would be hundreds of years before anything even remotely like a human mind”, he said in a recent interview.
Now? “This started happening at an accelerating pace, where unreachable goals and things that computers shouldn't be able to do started toppling. …systems got better and better at translation between languages, and then at producing intelligible responses to difficult questions in natural language, and even writing poetry. …The accelerating progress, has been so unexpected, so completely caught me off guard, not only myself but many, many people, that there is a certain kind of terror of an oncoming tsunami that is going to catch all humanity off guard.”
Similarly, during a Senate Judiciary Committee hearing last month, acclaimed leading AI researcher Yoshua Bengio said “I and many others have been surprised by the giant leap realized by systems like ChatGPT.”
In my role as a grantmaker, I’ve heard many ML academics express similar sentiments in private over the last year. In particular, I’ve spoken to many researchers who were specifically surprised by the programming and reasoning abilities of GPT-4 (even after seeing the capabilities of the free version of ChatGPT).
Another surprise ahead?
In 2021, most people were systematically and severely underestimating progress in language models. After a big leap forward in 2022, it looks like ML experts improved in their predictions of benchmarks like MMLU and MATH — but many still failed to anticipate the qualitative milestones achieved by ChatGPT and then GPT-4, especially in reasoning and programming.
I think many experts will soon be surprised yet again. Most importantly, ML experts and superforecasters both seem to be massively underestimating future spending on training runs. In the XPT tournament mentioned earlier, both groups predicted that the most expensive training run in 2030 would only cost around $100-180M. Instead, I think that the largest training run will probably cross $1 billion by 2025. This rapid scaleup will probably drive another qualitative leap forward in capability like what we saw over the last 18 months.
I’d be really excited for ML researchers to register their forecasts about what AI systems built on language models will be able to do in the next couple of years. I think we need to get good at predicting what language models will be able to do — in the real world, not just on benchmarks. Massively underestimating near-future progress could be very risky.


The XPT forecast about compute in 2030 still boggles my mind. I'm genuinely confused what happened there. Is anybody reading this familiar with the answer?
Reminds me of this:
A kind of conservativeness of "expert" opinion that doesn't correctly appreciate (rapid) exponential growth.
I think it’s also just very difficult for experts to adopt a new paradigm. In transportation the experts consistently overestimate.
Can you share a link to the source of this chart? The current link shows me a jpg and nothing else.
Source is here. (I've not read the article - I've seen the chart (or variations of it) a bunch of times before and just googled for the image.)
FWIW you can see more information, including some of the reasoning, on page 655 (# written on pdf) / 659 (# according to page searcher) of the report. (H/t Isabel.) See also page 214 for the definition of the question.
Some tidbits:
Experts started out much higher than superforecasters, but updated downwards after discussion. Superforecasters updated a bit upward, but less: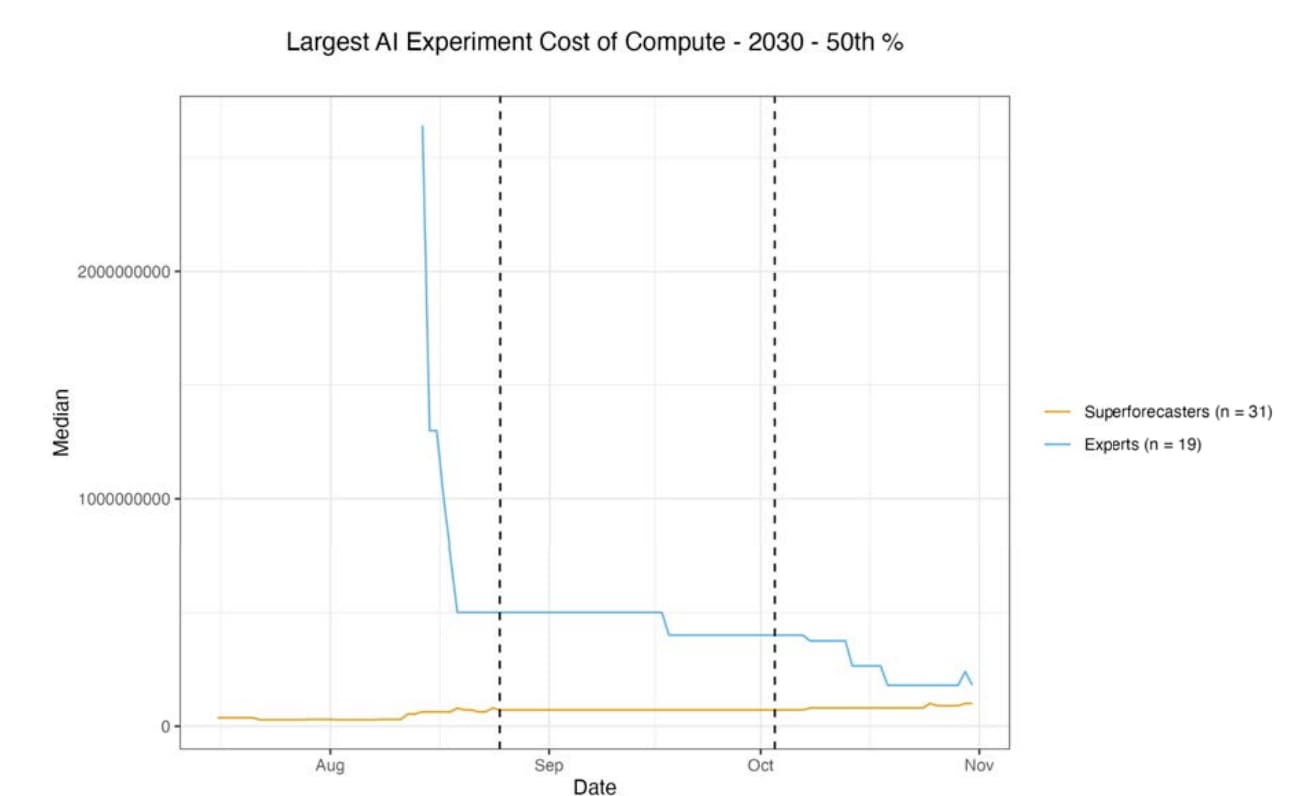
(Those are billions on the y-axis.)
This was surprising to me. I think the experts' predictions look too low even before updating, and look much worse after updating!
The part of the report that talks about "arguments given for lower forecasts". (The footnotes contain quotes from people expressing those views.)
(This last bullet point seems irrelevant to me. The question doesn't specify that the experiments has to be public, and "In the absence of an authoritative source, the question will be resolved by a panel of experts.")
Thanks!
I think this is evidence for a groupthink phenomenon amongst superforecasters. Interestingly my other experiences talking with superforecasters have also made me update in this direction (they seemed much more groupthinky than I expected, as if they were deferring to each other a lot. Which, come to think of it, makes perfect sense -- I imagine if I were participating in forecasting tournaments, I'd gradually learn to reflexively defer to superforecasters too, since they genuinely would be performing well.)