Comments
 While the framework is mathematical, the maths in these four cases turns out to simplify dramatically, so anyone should be able to follow it.
While the framework is mathematical, the maths in these four cases turns out to simplify dramatically, so anyone should be able to follow it.Existential risk, and an alternative framework
One common issue with “existential risk” is that it’s so easy to conflate it with “extinction risk”. It seems that even you end up falling into this use of language. You say: “if there were 20 percentage points of near-term existential risk (so an 80 percent chance of survival)”. But human extinction is not necessary for something to be an existential risk, so 20 percentage points of near-term existential risk doesn’t entail an 80 percent chance of survival. (Human extinction may also not be sufficient for existential catastrophe either, depending on how one defines “humanity”))
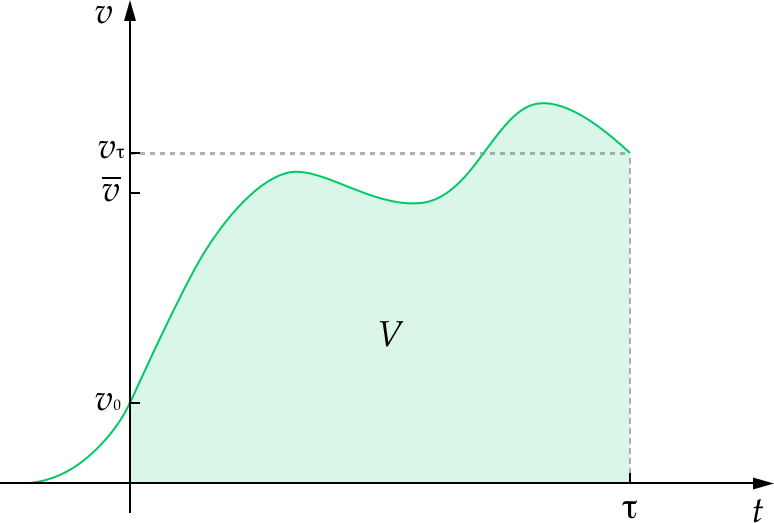
Relatedly, “existential risk” blurs together two quite different ways of affecting the future. In your model: . (That is: The value of humanity's future is the average value of humanity's future over time multiplied by the duration of humanity's future.)
This naturally lends itself to the idea that there are two main ways of improving the future: increasing and increasing .
In What We Owe The Future I refer to the latter as “ensuring civilisational survival” and the former as “effecting a positive trajectory change”. (We’ll need to do a bit of syncing up on terminology.)
I think it’s important to keep these separate, because there are plausible views on which affecting one of these is much more important than affecting the other.
Some views on which increasing is more important:
- If the future is of zero or net-negative value
- If large drops in future population size are not of enormous importance (e.g. the average view, variable-value views)
- If nonhuman-originating civilisation would use the resources that we would use, and is similarly good
Some views on which increasing is more important:
- If there’s a “low” upper bound on value, which we expect almost all future civilisations to meet
- If think that moral convergence, conditional on survival, is very likely
What’s more, changes to are plausible binary, but changes to are not. Plausibly, most probability mass is on being small (we go extinct in the next thousand years) or very large (we survive for billions of years or more). But, assuming for simplicity that there’s a “best possible” and “worst possible” future, could take any value between 100% and -100%. So focusing only on “drastic” changes, as the language of “existential risk” does, makes sense for changes to , but not for changes to .


Thank you for the post! I have a question: I wonder whether you think the trajectory to be shaped should be that of all sentient beings, instead of just humanity? It seems to me that you think that we ought to care about the wellbeing of all sentient beings. Why isn't this prinicple extraopolated when it comes to longtermism?
For instance, from the quote below from the essay, it seems to me that your proposal's scope doesn't neccessarily include nonhuman animals. "For example, a permanent improvement to the wellbeing of animals on earth would behave like a gain (though it would require an adjustment to what v(⋅) is supposed to be representing)."
Good point. I may not be clear enough on this in the piece (or even in my head). I definitely want to value animal wellbeing (positive and negative) in moral choices. The question is whether this approach can cleanly account for that, or if it would need to be additional. Usually, when I focus on the value of humanity (rather than all animals) it is because we are the relevant moral agent making the choices and because we have tremendous instrumental value — in part because we can affect other species for good or for ill. That works for defining existential risk as I do it via instrumental value.
But for these curves, I am trying to focus on intrinsic value. Things look quite different with instrumental value, as the timings of the benefits change. e.g. if we were to set up a wonderful stable utopia in 100 years, then the instrumental value of that is immense. It is as if all the intrinsic value of that utopia is scored at the moment in 100 years (or in the run up to it). Whereas, the curves are designed to track when the benefits are actually enjoyed.
I also don't want them to track counterfactual value (how much better things are than they would have been) as I think that is cleaner to compare options by drawing a trajectory for each option and then compare those directly (rather than assuming a default and subtracting it off every alternate choice).
It isn't trivial to reconcile these things. One approach would be to say the curve represents the instrumental effects of humanity on intrinsic value of all beings at that time. This might work, though does have some surprising effects, such as that even after our extinction, the trajectory might not stay at zero, and different trajectories could have different behaviour after our extinction.
This seems very natural to me and I'd like us to normalise including non-human animal wellbeing, and indeed the wellbeing of any other sentience, together with human wellbeing in analyses such as these.
We should use a different term than "humanity". I'm not sure what the best choice is, perhaps "Sentientity" or "Sentientkind".
On your last point, I really like “sentientkind”, but the one main time I used it (when brainstorming org names) I received feedback from a couple of non-EAs that sentientkind sounds a bit weird and sci-fi and thus might not be the best term. (I've not managed to come up with a better alternative for full-moral-circle-analogue-to-“humankind”, though.)
Thank you for the reply, Toby. I agree that humanity have instrumental values to all sentient beings. And I am glad that you want to include animals when you say shaping the future.
I wonder why you think this would be surprising? If humans are not the only beings who have intrinsic values, why is it surprising that there will be values left after humans go extinct?
It's because I'm not intending the trajectories to be a measure of all value in the universe, only the value we affect through our choices. When humanity goes extinct, it no longer contributes intrinsic value through its own flourishing and it has no further choices which could have instrumental value, so you might expect its ongoing value to be zero. And it would be on many measures.
Setting up the measures so that it goes to zero at that point also greatly simplifies the analysis, and we need all the simplification we can get if we want to get a grasp on the value of the longterm future. (Note that this isn't saying we should ignore effects of our actions on others, just that if there is a formal way of setting things up that recommends the same actions but is more analytically tractable, we should use that.)