Comments
Sign up here (a) or browse past newsletters here (a).
Replication Markets (a) was a project to research how well prediction markets could predict whether papers would replicate. They are paying out (a) $142k in cash rewards for the prediction markets part of the experiment. This corresponds to 121 resolved questions, which includes 12 meta-questions and 30 about covid papers.
The leaderboard for users is here (a). I won a mere $809, and I don't remember participating all that much. In particular, I was excited at the beginning but lost interest because a user—or a bot—named "unipedal" seemed like it was taking all the good opportunities.
Now, a long writeup by "unipedal" himself can be read at How I Made $10k Predicting Which Studies Will Replicate (a). The author started out with a simple quantitative model based on Altmejd et al. (2019) (a)
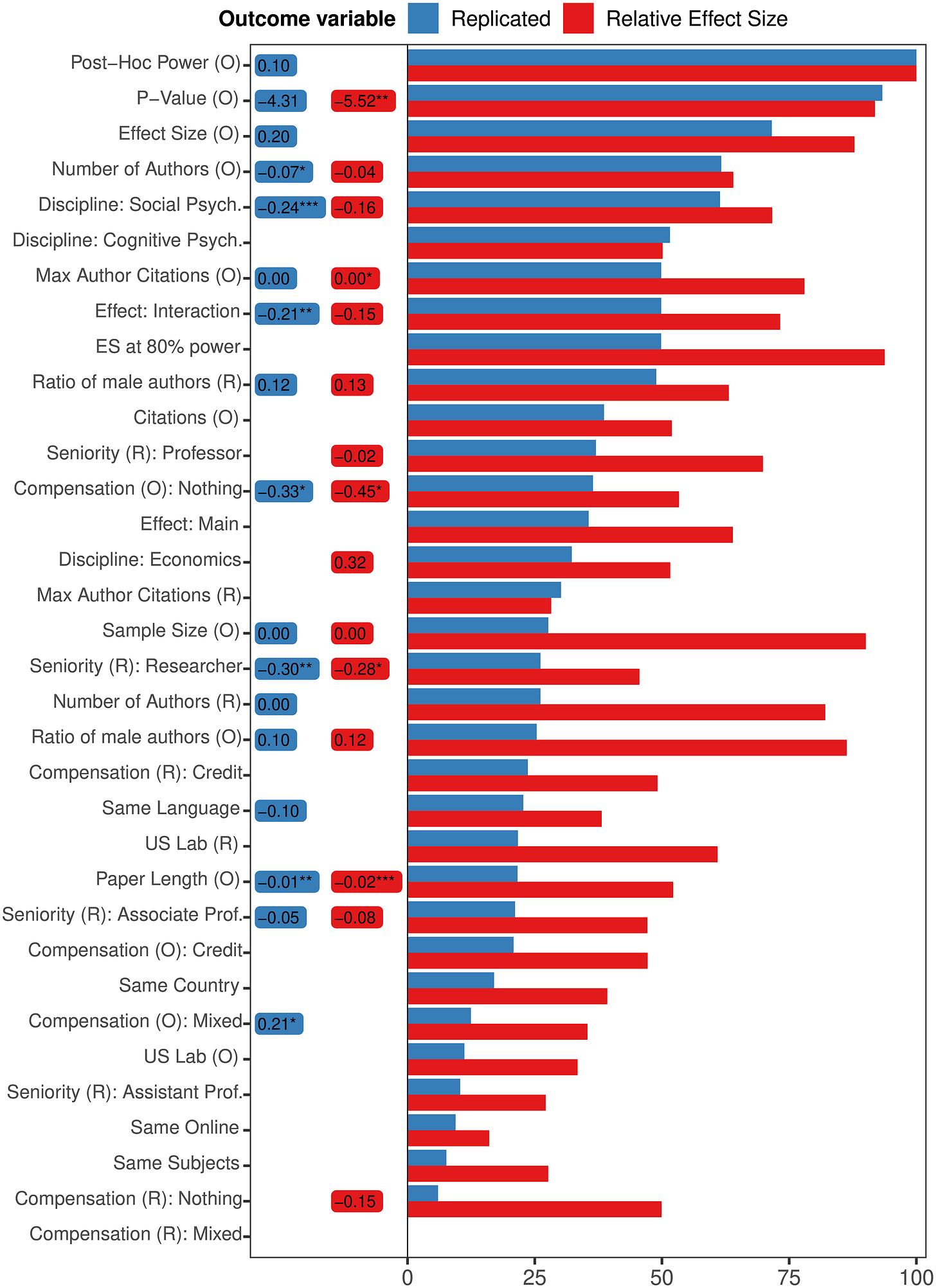
But in later rounds, he dropped the quantitative model, and started "playing the market". That is, he found out that trying to predict how the market will move is more profitable than giving one's own best guess. Unipedal then later automated his trades when the market API was opened to users.
In contrast, I participated in a few rounds and put in 10x less effort while earning much more than 1/10th of the rewards. As unipedal points out, this is backwards:
...I think one of the most important aspects of "ideal" prediction markets is that informed traders can compound their winnings, while uninformed traders go broke. The market mechanism works well because the feedback loop weeds out those who are consistently wrong. This element was completely missing in the RM [Replication Markets] project.
The same author previously wrote: What's Wrong with Social Science and How to Fix It: Reflections After Reading 2578 Papers (a), which is also based on his experiences with the Replication Markets competition.
Besides Replication Markets, DARPA has also founded another group to predict replications through their SCORE (a) program. Based on preliminary results, this second group (a) seems like they beat Replication Markets by using a more Delphi-like (a) methodology to elicit predictions.
It has been an active month for Metaculus.
For starters, they rehauled (a) their scoring system for tournaments. Then, Metaculus' Journal (a) started to give fruit: The article on forecasts of Human-Level Language Models (a) (also on LessWrong here (a)) was of fairly high quality.
Metaculus also started to keep track of the accuracy of a small number of Public Figures (a). Because Metaculus has so many questions, every time one of these figures makes a public prediction, it is likely enough that Metaculus also has a prediction on the same issue. Over time, this will allow Metaculus to see who is generally more accurate. This is a more adversarial version of Tetlock's original Alpha Pundit (a) idea: instead of having experts willingly participate, Metaculus is just passively keeping track of how bad they are. Kudos!
Two comments worth highlighting from SimonM's (a) list of top comments from Metaculus this past November) (a) are:
In addition, Metaculus and its community worked at full speed to put up questions and produce forecasts on the Omicron (a) variant (a). Metaculus also added more questions to the Keep Virginia Safe Tournament) (a), and increased the price pool somewhat to $2,500.
Polymarket saw some extremely large swings, where 1:250 (a) and 1:700 (a) underdogs ended up winning. h/t @Domahhhh (a)
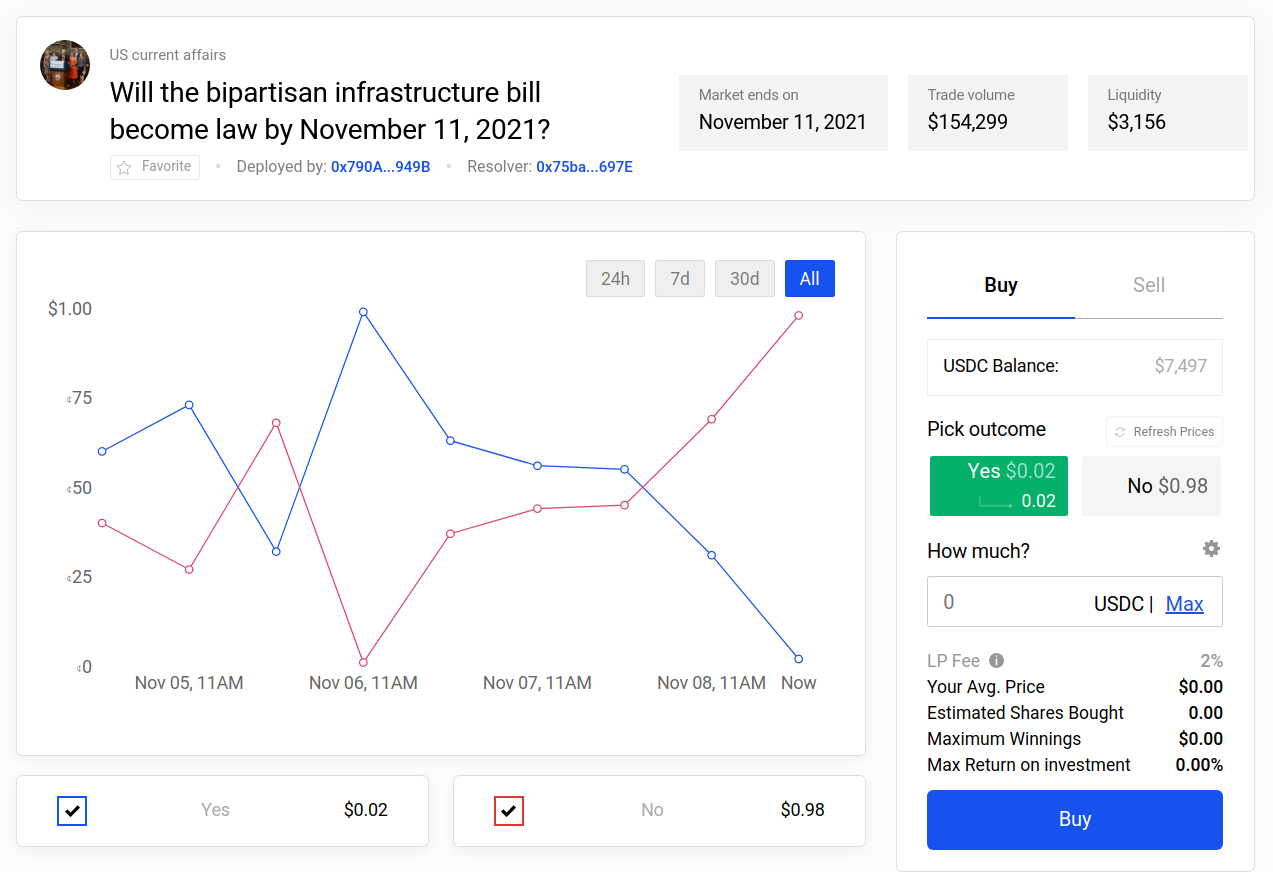
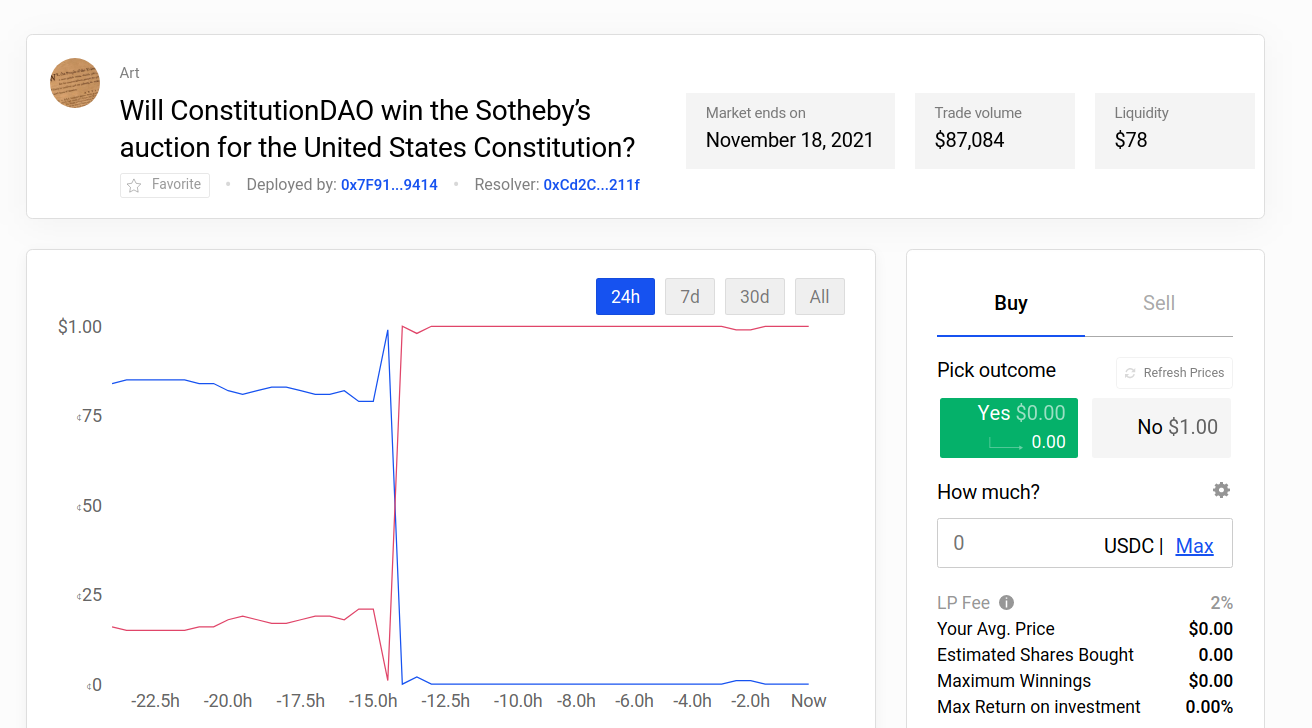
Zvi positively covers some Polymarket markets on Covid here (a).
Polymarket also added support for Metamask (a), one of the most popular crypto-wallets, making Polymarket ever more mainstream. They also had a bit of a brouhaha on a market on the number of exoplanets (a) discovered, where the resolution source pointed to two different numbers.
Augur—a set of pioneering prediction market contracts on Ethereum and the community around it—is creating a decentralized autonomous organization (a), AugurDAO (a). I get the impression that the original developers have gotten tired of supporting Augur, whose current focus on sports markets merely makes it a very slow sportsbook.
But the move is also consistent with Augur's initial ethos of being decentralized. For example, the Forecast Foundation (a) which supports Augur's development, seems to live under Estonian jurisdiction (a), whereas a DAO arguably lives under no jurisdiction.
The Foresight Institute is hosting a "Vision Weekend" (a) in the US and France. Although I remembered the Foresight Institute as something that Eric Drexler founded before he went on to do other things (a), I did find some familiar names in the list of presenters (a), and browsing the details the event is probably going to be of higher quality than I would have thought.
The Anticipation Hub is hosting a "Global Dialogue Platform on Anticipatory Humanitarian Action (a)", hosted online from the 7th to the 9th of December. Although it seems more focused on global health and development topics, it might be of interest to NGOs around the forecasting space more generally.
The Global Priorities Institute (a) is dipping its toes into forecasting. As one might expect, so far there is a lot of academically-flavored discussions, but very little actual forecasting.
Hedgehog Markets had an NFT-minting event (a), where users could buy NFTs which they will be able to use to participate in competitions closed-off to non-NFT holders. I don’t see the appeal, but others did and spent around $500k on these tokens (5000 NFTs at 0.5 SOL (a) per token).
A former US Commodity Futures Trading Commission commissioner joined Kalshi’s board (a).
Hypermind started a new contest (a) on the "future of Africa", with $6000 in prize money.
There is a fairly neat calibration app (a) based on the exercises from The Scout Mindset.
I've added Peter Wildeford's pubicly available predictions to Metaforecast:
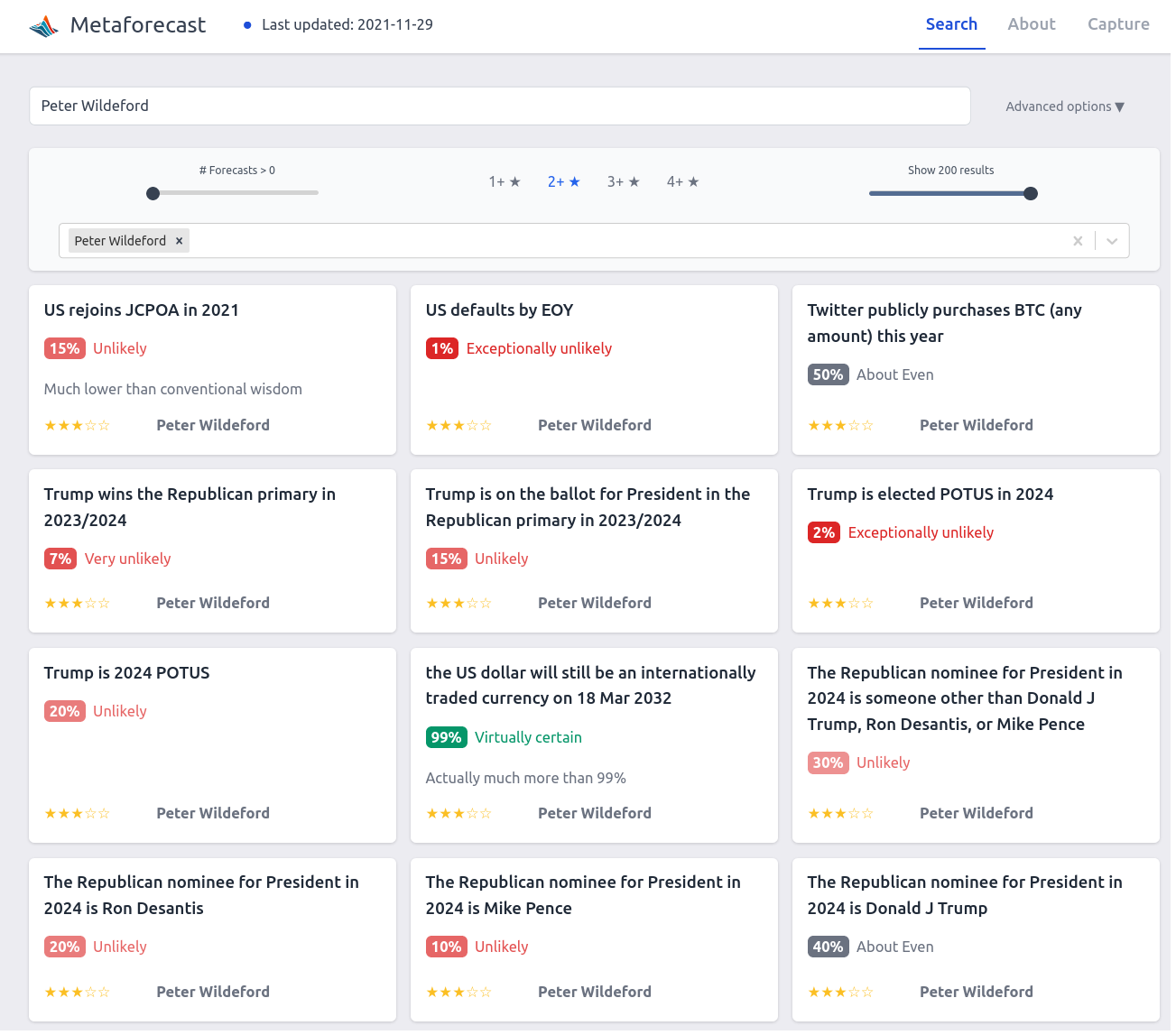
On the negative side, Metaforecast is experiencing some difficulties with updating with new forecasts, which I hope to get fixed in the coming week.
The Economist featured a full page with forecasts from Good Judgment Open (a) on their "The World in 2022" edition.
Reuters reports that Climate change extremes spur U.N. plan to fund weather forecasting (a). My impression is that climate change fears are being used to fund much-needed bog-standard weather forecasting. I have mixed feelings about this.
An Excel competitor with some forecasting functionality, Pigment (a), raises $73M (a).
Joe Carlsmith writes down his thoughts on Solomonoff induction (a) (see a decent introduction of the concept here (a)). Although I was already familiar with the concept, I still feel like I learnt a bunch:
Tanner Greer of The Scholar's Stage has a new piece on Sino-American Competition and the Search For Historical Analogies (a). His main point is that the tensions around Taiwan break the analogy between the current relationship between the US and China and the relationship between the US and the USSR during the Cold War.
Jaime Sevilla posts A Bayesian Aggregation Paradox (a): There is no objective way of summarizing a Bayesian update over an event with three outcomes A:B:C as an update over two outcomes A:¬A. From the comments:
Imagine you have a coin that's either fair, all-heads, or all-tails. If your prior is "fair or all-heads with probability 1/2 each", then seeing heads is evidence against "fair". But if your prior is "fair or all-tails with probability 1/2 each", then seeing heads is evidence for "fair". Even though "fair" started as 1/2 in both cases. So the moral of the story is that there's no such thing as evidence for or against a hypothesis, only evidence that favors one hypothesis over another.
Are "superforecasters" a real phenomenon? (a). David Manheim, a superforecaster, answers:
So in short, I'm unconvinced that superforecasters are a "real" thing, except in the sense that most people don't try, and people who do will do better, and improve over time. Given that, however, we absolutely should rely on superforecasters to make better predictions that the rest of people - as long as they continue doing the things that make them good forecasters.
Note to the future: All links are added automatically to the Internet Archive, using this tool (a). "(a)" for archived links was inspired by Milan Griffes (a), Andrew Zuckerman (a), and Alexey Guzey (a).
It is curious to reflect that out of all the "experts" of all the schools, there was not a single one who was able to foresee so likely an event as the Russo-German Pact of 1939. And when news of the Pact broke, the most wildly divergent explanations were of it were given, and predictions were made which were falsified almost immediately, being based in nearly every case not on a study of probabilities but on a desire to make the U.S.S.R. seem good or bad, strong or weak. Political or military commentators, like astrologers, can survive almost any mistake, because their more devoted followers do not look to them for an appraisal of the facts but for the stimulation of nationalistic loyalties
— George Orwell, Notes on Nationalism (a), 1945, h/t Scott Alexander.


The GPI link goes to their homepage. Is there a more specific URL for the claim that "The Global Priorities Institute is dipping its toes into forecasting"?
No. But on the other hand, I did attend a couple of their meetings/activities on the topic this past month.