Comments
To my understanding, Google has better infosec than OpenAI and Anthropic. They have much more experience protecting assets.
To my understanding, Google has better infosec than OpenAI and Anthropic. They have much more experience protecting assets.
I share this impression. Unfortunately it's hard to capture the quality of labs' security with objective criteria based on public information. (I have disclaimers about this in 4-6 different places, including the homepage.) I'm extremely interested in suggestions for criteria that would capture the ways Google's security is good.
I mean Google does basic things like use Yubikeys where other places don't even reliably do that. Unclear what a good checklist would look like, but maybe one could be created.
The broader question I'm confused about is how much to update on the local/object-level of whether the labs are doing "kind of reasonable" stuff, vs what their overall incentives and positions in the ecosystem points them to doing.
eg your site puts OpenAI and Anthropic as the least-bad options based on their activities, but from an incentives/organizational perspective, their place in the ecosystem is just really bad for safety. Contrast with, e.g., being situated within a large tech company[1] where having an AI scaling lab is just one revenue source among many, or Meta's alleged "scorched Earth" strategy where they are trying very hard to commoditize the component of LLMs.
eg GDM employees have Google/Alphabet stock, most of the variance in their earnings isn't going to come from AI, at least in the short term.
Thanks for doing this! This is one of those ideas that I've heard discussed for a while but nobody was willing to go through the pain of actually making the site; kudos for doing so.
Very easy to read. Props on the design.
Cool idea, thanks for working on it.
According to this article, only Deepmind gave the UK AI Institute (partial?) access to their model before release. This seems like a pro-social thing to do so maybe this could be worth tracking in some way if possible.
This is a great project idea!
OpenAI has made a hard commitment to safety by allocating 20% compute (~20% of budget) for the superalignment team. That is a huge commitment which isn't reflected in this.
I agree such commitments are worth noticing and I hope OpenAI and other labs make such commitments in the future. But this commitment is not huge: it's just "20% of the compute we've secured to date" (in July 2023), to be used "over the next four years." It's unclear how much compute this is, and with compute use increasing exponentially it may be quite little in 2027. Possibly you have private information but based on public information the minimum consistent with the commitment is quite little.
It would be great if OpenAI or others committed 20% of their compute to safety! Even 5% would be nice.
I've heard OpenAI employees talk about the relatively high amount of compute superalignment has (complaining superalignment has too much and they, employees outside superalignment, don't have enough). In conversations with superalignment people, I noticed they talk about it as a real strategic asset ("make sure we're ready to use our compute on automated AI R&D for safety") rather than just an example of safety washing. This was something Ilya pushed for back when he was there.

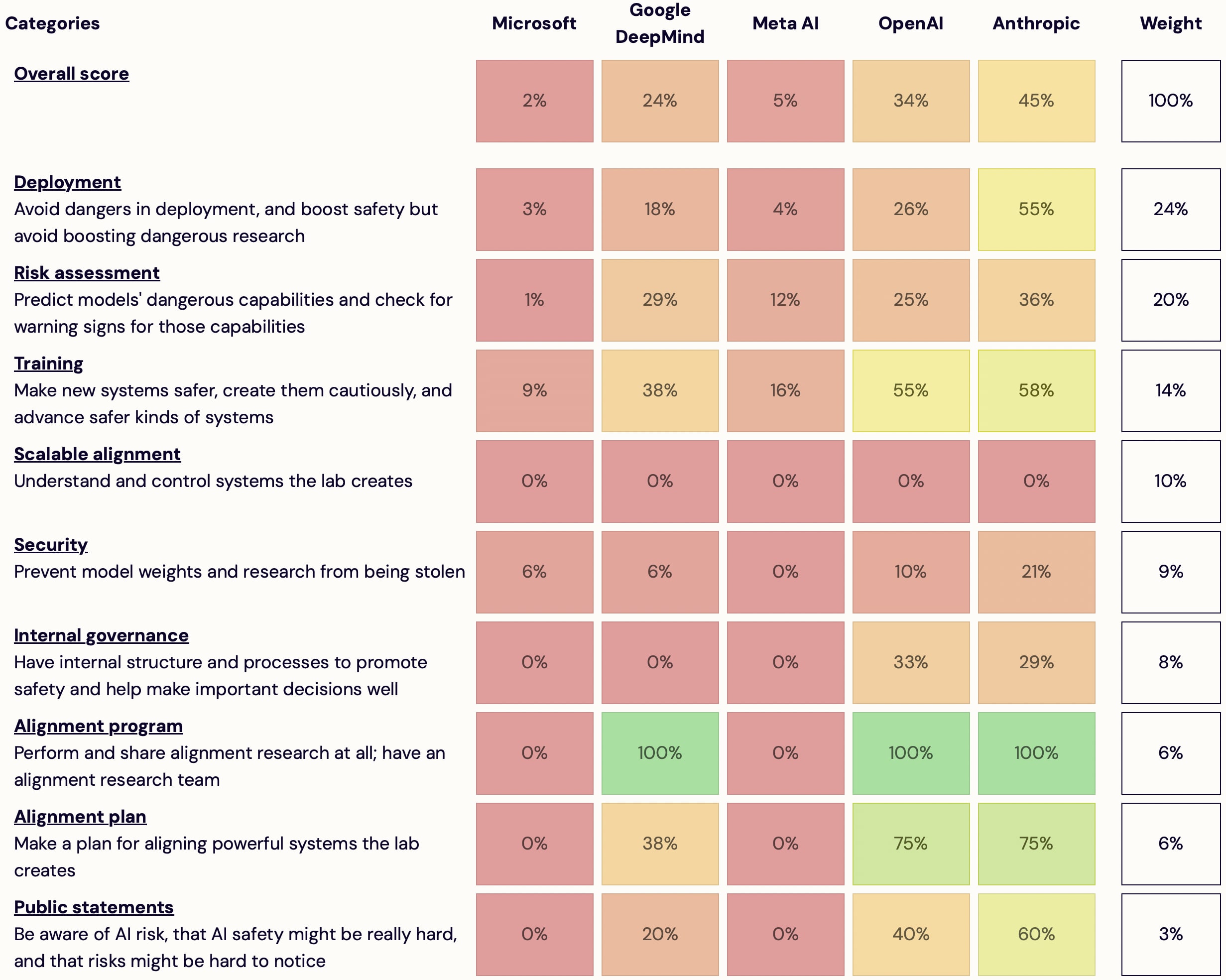
I'm launching AI Lab Watch. I collected actions for frontier AI labs to improve AI safety, then evaluated some frontier labs accordingly.
It's a collection of information on what labs should do and what labs are doing. It also has some adjacent resources, including a list of other safety-ish scorecard-ish stuff.
(It's much better on desktop than mobile — don't read it on mobile.)
It's in beta—leave feedback here or comment or DM me—but I basically endorse the content and you're welcome to share and discuss it publicly.
It's unincorporated, unfunded, not affiliated with any orgs/people, and is just me.
Some clarifications and disclaimers.
How you can help:
I think this project is the best existing resource for several kinds of questions, but I think it could be a lot better. I'm hoping to receive advice (and ideally collaboration) on taking it in a more specific direction. Also interested in finding an institutional home. Regardless, I plan to keep it up to date. Again, I'm interested in help but not sure what help I need.
I could expand the project (more categories, more criteria per category, more labs); I currently expect that it's more important to improve presentation stuff but I don't know how to do that; feedback will determine what I prioritize. It will also determine whether I continue spending most of my time on this or mostly drop it.
I just made a twitter account. I might use it to comment on stuff labs do.
Thanks to many friends for advice and encouragement. Thanks to Michael Keenan for doing most of the webdev. These people don't necessarily endorse this project.

I think this is a great idea! Is there a way to have two versions:
Content like this is only as good as the number of people that see it, and while its detail would necessarily be reduced in the meme-able version, I think it is still worth doing.
The Alliance for Animals does this in the lead up to elections and it gets spread widely: https://www.allianceforanimals.org.au/nsw-election-2023
Yep. But in addition to being simpler, the version of this project optimized for getting attention has other differences:
Even if I could do this, it would be effortful and costly and imperfect and there would be tradeoffs. I expect someone else will soon fill this niche pretty well.
Hi Zach! To clarify, are you basically saying you don't want to improve the project much more than where you've got it to? I think it is possible you've tripped over a highly impactful thing here!
Not necessarily. But:
"And as I said, I expect such a project to appear soon."
I dont know whether to read this as "Zach has some inside information that gives him high confidence it will exist" or "Zach is doing wishful thinking" or something else!
What do you consider the purpose or theory of change of this project? I assumed it was to put pressure on the AI labs to improve along these criteria, which presumably requires some level of public attention. Do you see it more as a way for AI safety people to keep tabs on the status of these labs?
The original goal involved getting attention. Weeks ago, I realized I was not on track to get attention. I launched without a sharp object-level goal but largely to get feedback to figure out whether to continue working on this project and what goals it should have.
I think getting attention would increase the impact of this project a lot and is probably pretty doable if you are able to find an institutional home for it. I agree with Yanni's sentiment that it is probably better to improve on this project than to wait for another one that is more optimized for public attention to come along (though am curious why you think the latter is better).