Comments

I'm excited about this series!
I would be curious what your take is on this blog post from OpenAI, particularly these two graphs:
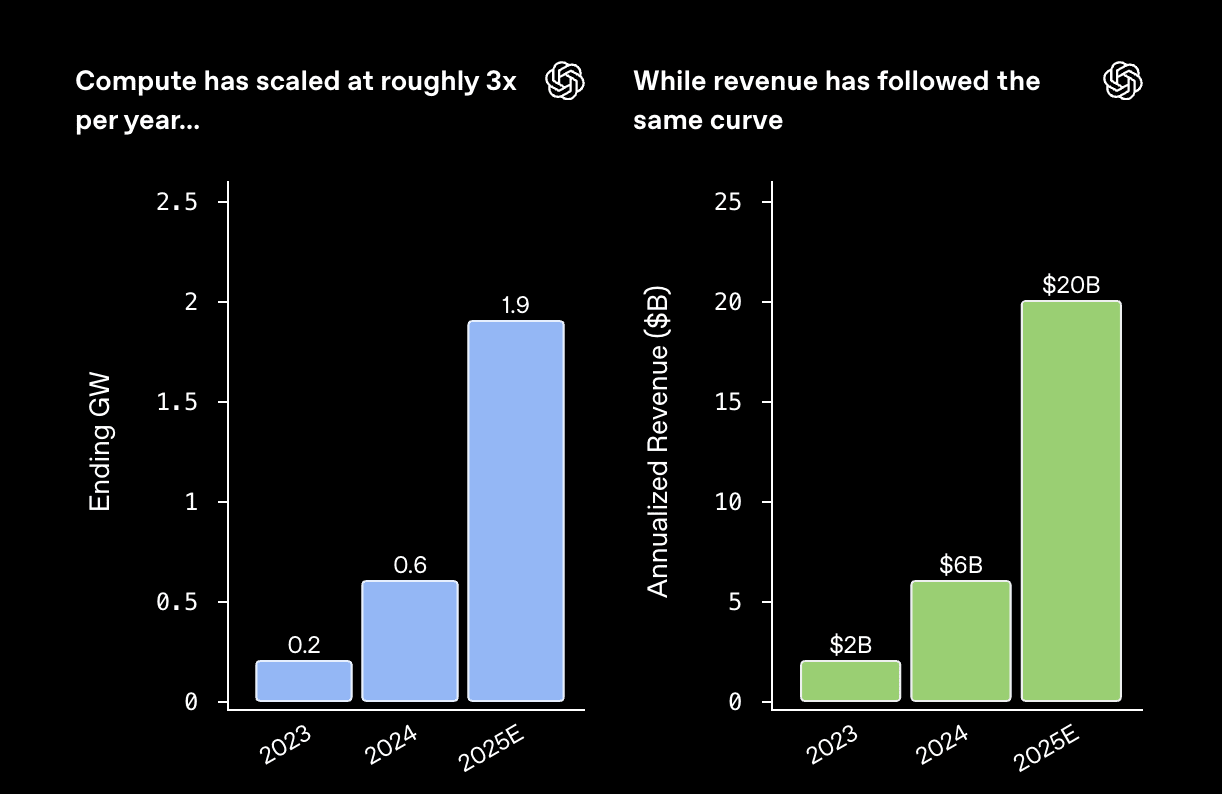
Investment in compute powers leading-edge research and step-change gains in model capability. Stronger models unlock better products and broader adoption of the OpenAI platform. Adoption drives revenue, and revenue funds the next wave of compute and innovation. The cycle compounds.
While their argument is not very precise, I understand them to be saying something like, "Sure, it's true that the costs of both inference and training are increasing exponentially. However, the value delivered by these improvements is also increasing exponentially. So the economics check out."
A naive interpretation of e.g. the METR graph would disagree: humans are modeled as having a constant hourly wage, so being able to do a task which is 2x as long is precisely 2x as valuable (and therefore can't offset a >2x increase in compute costs). But this seems like an implausible simplification.
Do we have any evidence on how the value of models changes with their capabilities?


{kind=link}
A few points to clarify my overarching view:
I feel confused about this point because I thought the argument you were making implies a non-constant "tailwind." E.g. for the next generation these factors will be 1/2 as important as before, then the one after that 1/4, and so on. Am I wrong?
Yeah, it isn't just like a constant factor slow-down, but is fairly hard to describe in detail. Pre-training, RL, and inference all have their own dynamics, and we don't know if there will be new good scaling ideas that breathe new life into them or create a new thing on which to scale. I'm not trying to say the speed at any future point is half what it would have been, but that you might have seen scaling as a big deal, and going forward it is a substantially smaller deal (maybe half as big a deal).
Thanks, that's helpful. Do you have a sense of where we are on the current S-curve? E.g., if capabilities continue to progress in a straight line through the end of this year, is that evidence that we have found a new S-curve to stack on the current one?
That's a great question. I'd expect a bit of slowdown this year, though not necessarily much. e.g. I think there is a 10x or so possible for RL before RL-training-compute reaches the size of pre-training compute, and then we know they have enough to 10x again beyond that (since GPT-4.5 was already 10x more), so there are some gains still in the pipe there. And I wouldn't be surprised if METR timelines keep going up in part due to increased inference spend (i.e. my points about inference scaling not being that good are to do with costs exploding, so if a cost-insensitive benchmark is going on, it might not register on it all that much). There is also room for more AI-research or engineering improvements to these things, and a lump of new compute coming in, making it a bit messy.
Overall, I'd say my predictions are more about appreciable slowing in 2027+ rather than 2026.
And I'll add that RL training (and to a lesser degree inference scaling) is limited to a subset of capabilities (those with verifiable rewards and that the AI industry care enough about to run lots of training on). So progress on benchmarks has been less representative of how good they are at things that aren't being benchmarked than it was in the non-reasoning-model era. So I think the problems of the new era are somewhat bigger than the effects that show up in benchmarks.
"All kinds of compute scaling are quite inefficient on most standard metrics. There are steady gains, but they are coming from exponentially increasing inputs."
Is this kind of the opposite of Moore's law lol?