Executive summary: The post argues that a subtle wording error in one LEAP survey question caused respondents and report authors to conflate three distinct questions, making the published statistic unsuitable as evidence about experts’ actual beliefs about future AI progress.
Key points:
The author says the report’s text described the statistic as if experts had been asked the probability of “rapid” AI progress (question 0), but the footnote actually summarized a different query about how LEAP panelists would vote (question 1).
The author states that the real survey item asked for the percentage of 2030 LEAP panelists who would choose “rapid” (question 2), which becomes a prediction of a future distribution rather than a probability of rapid progress.
The author argues that questions 0, 1, and 2 yield different numerical answers even under ideal reasoning, so treating responses to question 2 as if they reflected question 0 was an error.
The author claims that respondents likely misinterpreted the question, given its length, complexity, and lack of reminder about what was being asked.
The author reports that the LEAP team updated the document wording to reflect the actual question and discussed their rationale for scoreable questions but maintained that the issue does not affect major report findings.
The author recommends replacing the question with a direct probability-of-progress item plus additional scoreable questions to distinguish beliefs about AI progress from beliefs about panel accuracy.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, andcontact us if you have feedback.
I can’t thank titotal enough for writing this post and for talking to the Forecasting Research Institute about the error described in this post.
I’m also incredibly thankful to the Forecasting Research Institute for listening to and integrating feedback from me and, in this case, mostly from titotal. It’s not nothing to be responsive to criticism and correction. I can only express appreciation for people who are willing to do this. Nobody loves criticism, but the acceptance of criticism is what it takes to move science, philosophy, and other fields forward. So, hallelujah for that.
I want to be clear that, as titotal noted, we’re just zeroing in here on one specific question discussed in the report, out of 18 total. It is an unfortunate thing that you can work hard on something that is quite large in scope and it can be almost entirely correct (I haven’t reviewed the rest of the report, but I’ll give the benefit of the doubt), but then the discussion focuses around the one mistake you made. I don’t want research or writing to be a thankless task that only elicits criticism, and I want to be thoughtful about how to raise criticism in the future.
For completeness, to make sure readers have a full understanding, I actually made three distinct and independent criticisms of this survey question and how it was reported. First, I noted that the probability of the rapid scenario was reported as an unqualified probability, rather than the probability of the scenario being the best matching of the three — “best matching” is the wording the question used. The Forecasting Research Institute was quick to accept this point and promise to revise the report.
Second, I raised the problem around the intersubjective resolution/metaprediction framing that titotal describes in this post. After a few attempts, I passed the baton to titotal, figuring that titotal’s reputation and math knowledge would make them more convincing. The Forecasting Research Institute has now revised the report in response, as well as their EA Forum post about the report.
Third, the primary issue I raised in my original post on this topic is about a potential anchoring effect or question wording bias with the survey question.[1] The slow progress scenario is extremely aggressive and optimistic about the amount of progress in AI capabilities between now and the end of 2030. I would personally guess the probability of AI gaining the sort of capabilities described in the slow progress scenario by the end of 2030 is significantly less than 0.1% or 1 in 1,000. I imagine most AI experts would say it’s unlikely, if presented with the scenario in isolation and asked directly about its probability.
For example, here is what is said about household robots in the slow progress scenario:
By the end of 2030 in this slower-progress future, AI is a capable assisting technology for humans; it can … conduct relatively standard tasks that are currently (2025) performed by humans in homes and factories.
Also:
Meanwhile, household robots can make a cup of coffee and unload and load a dishwasher in some modern homes—but they can’t do it as fast as most humans and they require a consistent environment and occasional human guidance.
Even Metaculus, which is known to be aggressive and optimistic about AI capabilities, and which is heavily used by people in the effective altruist community and the LessWrong community, where belief in near-term AGI is strong, puts the median date for the question “When will a reliable and general household robot be developed?” in mid-2032. The resolution criteria for the Metaculus question are compatible with the sentence in the slow progress scenario, although those criteria also stipulate a lot of details that are not stipulated in the slow progress scenario.
An expert panel surveyed in 2020 and 2021 was asked, “[5/10] years from now, what percentage of the time that currently goes into this task can be automated?” and answered 47% for dish washing in 10 years, so in 2030 or 2031. I find this to be a somewhat confusing framing — what does it mean for 47% of the time involved in dish washing to be automated? — but it points to the baseline scenario in the LEAP survey involving contested questions and not just things we can take for granted.
Adam Jonas, a financial analyst at Morgan Stanley who has a track record of being extremely optimistic about AI and robotics (sometimes mistakenly so), and who the financial world interprets as having aggressive, optimistic forecasts, predicts that a “general-purpose humanoid” robot for household chores will require “technological progress in both hardware and AI models, which should take about another decade”, meaning around 2035. So, on Wall Street, even an optimist seems to be less optimistic than the LEAP survey’s slow progress scenario.
If the baseline scenario is more optimistic about AI capabilities progress than Metaculus, the results of a previous expert survey, and a Wall Street analyst on the optimistic end of the spectrum, then it seems plausible that the baseline scenario is already more optimistic than what the LEAP panelists would have reported as their median forecast if they had been asked in a different way. It seems way too aggressive as a baseline scenario. This makes it hard to know how to to interpret the panelists' answers (in addition to the interpretative difficulty raised by the problem described in titotal's post above).
I have also used the term “framing effect” to describe this before — following the Forecasting Research Institute and AI Impacts — but now checking again the definition of that term in psychology, it seems to specifically refer to framing the same information as positive or negative, which doesn’t apply here.
Perhaps they mentioned this elsewhere, but it could have added to their defence of this kind of question to note that 'third-person' questions like this are often asked to ameliorate social desirability and incentivise truth-telling, e.g. here or as in the bayesian truth serum. Of course, that's a separate question to whether this specific question was worded in the best way.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
The LEAP panel is a project run by the Forecasting Research institute to attempt to determine the views of a range of AI experts on how future AI progress will go. They recently released a white paper explaining the format of the panel, as well as showing a range of forecasting outcomes.
One of the questions in the survey was phrased in a manner that I think was confusing, and was subsequently misrepresented in the text of the report. After a back-and-forth, the team working on the report has corrected the wording in the paper.
I have written up this article because I think it is an interesting example of how even very subtle word choices can end up undermining, and potentially invalidating, a survey question. At the end, I provide a suggested improvement in the wording.
I'll note that this discussion is confined to one question only, out of the 18 asked in the report. In a later section, I will explain why I think it's still a matter of importance.
I want to thank Connacher Murphy and Ezra Karger from FRI for being willing to hear this criticism out and make adjustments to their report, and for looking over this article for factual errors. And I want to thank @Yarrow Bouchard 🔸for originally catching the mistake and convincing me of the mistakes validity.
Questions 0 and question 1:
This report summarises the findings of a panel of people with expertise in AI.
Here was a quote from page 32 of the report, before it was corrected:
Core statement in bold: “General capabilities: Lab leaders predict human-level or superhuman AI by 2026-2029, while our expert panel indicates longer timelines for superhuman capabilities. By 2030, the average expert thinks there is a 23% chance the world most closely mirrors an (“rapid”) AI progress scenario that matches some of these claims”
Now, before continuing, I want you to stop and think about what claim is being made here, and what type of question you think they asked to assess this. How would you phrase a survey question, if this was the type of thing you wanted to know?
I’m guessing you thought of something like the following, which I will call “question 0”:
“What is the probability that, in 2030, progress will be rapid?”[1]
I’m guessing, that, like me, you would guess it was a question posed to each expert, asking them “what is the chance that AI progress will be “rapid”?”. This is the type of thing we would really like to know!
But in the footnote, the question was summarized as follows (before being corrected):
“We ask participants the probability LEAP panelists will choose “slow progress,” “moderate progress,” or “rapid progress” as best matching the general level of AI progress.”
Now, reading this, what would you guess is the question that was asked of participants? I would say this would be something like:
Question 1: “In 2030, what is the probability that LEAP panelists will most commonly pick “rapid progress” as best matching the general level of AI progress over the previous five years?”
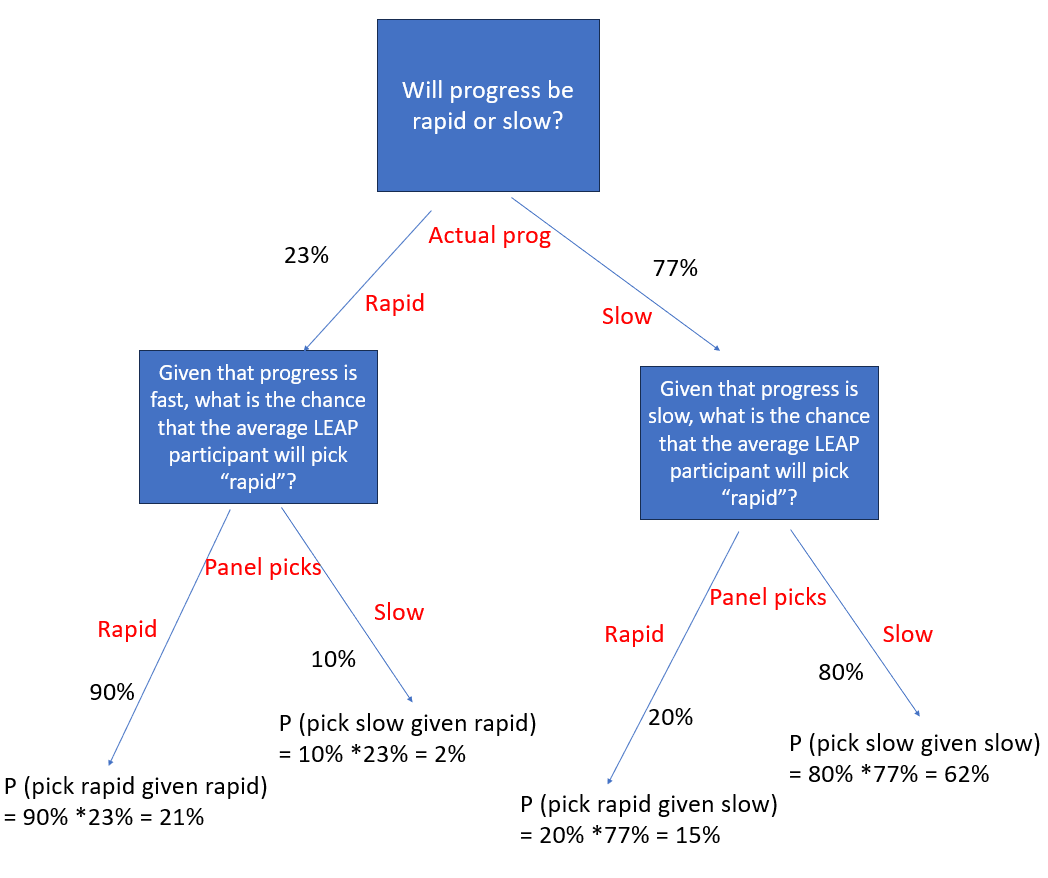
Question 1 is different from question 0, and would be asking something different from the core statement above. It would not be asking just a question about what the world will be like: it would be asking a combination of three questions involving conditional probability: (We will reduce the question to “rapid” or “not rapid” to simplify):
a) What is the probability that, in 2030, progress will be rapid?
b) Given that progress is rapid, what is the probability that the LEAP panelists in 2030 collectively choose “rapid” as best describing AI progress
c) Given that progress is slow, what is the probability that the LEAP panelists in 2030 collectively choose “rapid” as best describing AI progress
Suppose someone answers questions a, b and c, with 23%, 90%, and 20% respectively, indicating that they think rapid progress is unlikely and that the leap panel is somewhat fallible and slightly biased towards thinking progress is rapid. Then their calculations would go as illustrated in the following diagram:
They would think there was a 21% chance that LEAP picks “rapid” and is correct, and also a 15% chance that LEAP picks “rapid” and is incorrect. So their final answer to question 1 would be 21+15 = 36%. This is significantly higher than their actual believed probability of rapid progress, which is only 23%. [footnote: this doesn’t rely on the bias assumption: if you think the panel is 10% likely to get it wrong either way, the final estimate is 28%, which is till an overestimate].
So, this was one mistake: It would be inaccurate to report the answer to question 1 as the person’s belief in whether AI progress is rapid. The only way this question collapses back to the actual core statement about an expert’s actual view of AI progress is if they think there is a 100% chance that the panel will get it right. In any other situation, the percentage they give should be different from their actual belief, usually higher (if their initial estimate is low).
Question 2:
Unfortunately, it gets even more complicated than that, because the original footnote that I got Question 1 out of was also in error.
I will remind you of question 1, which was the footnote summary of the question:
Question 1: “In 2030, what is the probability that LEAP panelists will most commonly pick “rapid progress” as best matching the general level of AI progress over the previous five years?”
However, the actual question they asked is the equivalent of the following:
Question 1: “In 2030, what percentage of LEAP panelists will pick “rapid progress” as best matching the general level of AI progress over the previous five years?”
This is a very subtle difference. But it actually transforms this into a completely different question.
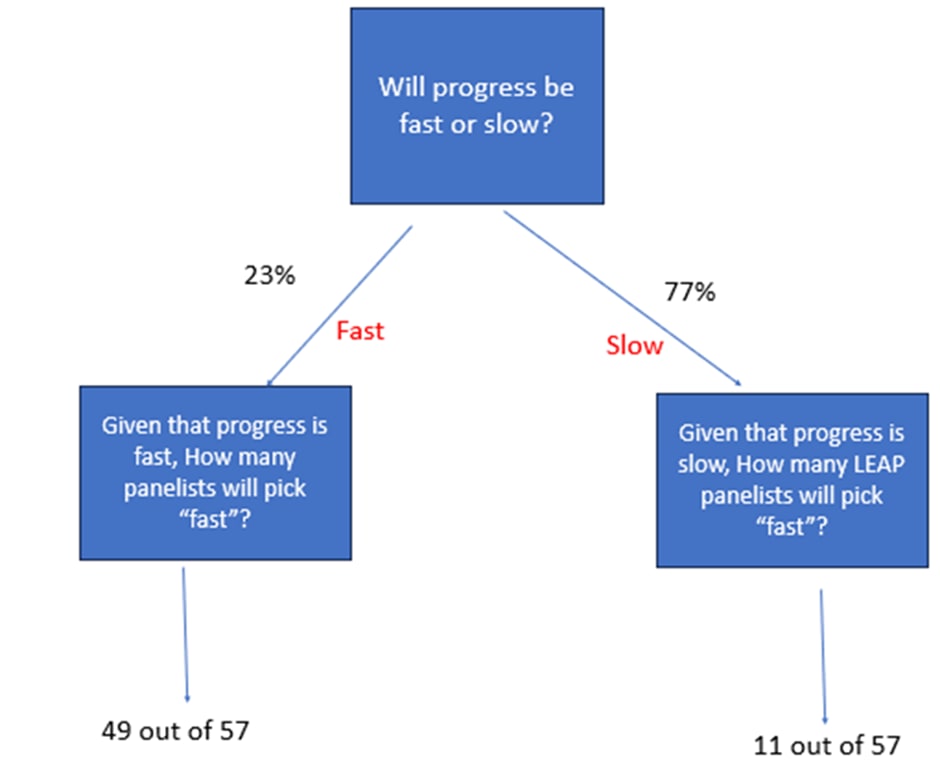
When we look at question 2, the key problem is that they are not being asked to estimate a probability at all. They are being asked to estimate a proportion of people. So, let’s say there are 57 people in the LEAP panel. The answer to question 2 becomes a guess of how many people will do a thing.
The problem with this is that, like in the answer to question 1, the number of people answering “rapid” will depend on what actually happens up to 2030.
For example, suppose if someone has a lot of faith in LEAP, their thinking becomes the following:
They think there is 23% chance that progress is fast, and so the number of panellists that answer “rapid” will be 49, and a 77% chance that progress is slow, and the number of panelists that will answer “rapid” is 13. [2]
So what are you meant to answer? How would you answer, when asked to estimate this number?
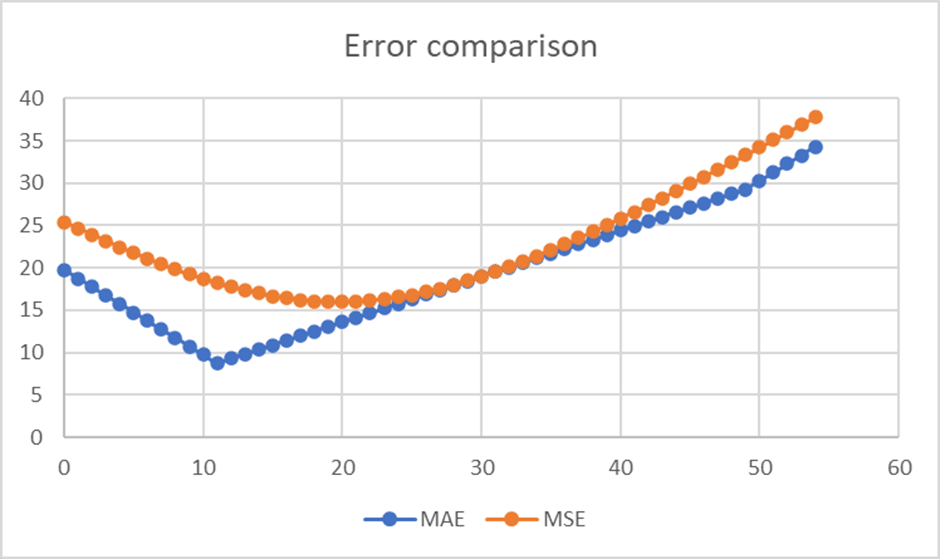
Well, it depends on how the question is “scored”. If answers are scored based on “mean squared error”, then the answer that minimises expected error is an answer of 20, or 35% of the panel, which is a weighted average of the two possibilities. If the scoring system had been based on Mean Absolute Error instead, then the mathematically optimal answer would be 11, or 20% of the panel. It turns out that this is scored on MSE, so an answer of 35% is the mathematically optimal answer.
Of course, this is a simplified, binaristic model: it doesn’t account for the answers in the case of moderate progress, or anything in between. To do better, you could distribute a probability mass of various futures and make a mathematical function of what the LEAP panel will say in all of them and mush them together and….
Actually, let’s stop ourselves there. Because it doesn’t actually matter what the optimal solution is if nobody is actually doing it.
This is meant to be a survey, not a maths problem! While plenty of the people on the panel are very smart, there is no reason to expect them to work any of this stuff out in the middle of a giant survey. We are not interested in how good they are at doing complex forecasting math, we want to know what they feel about AI progress!
Which question are they answering?
So now we have three different versions of a single question, question 0, 1 and 2, all of which will produce different answers, even with perfect reasoning.
The team writing the LEAP report actually asked question 2. But in a footnote they described question 1, and in the body text of the report, they described the results as if they had asked question 0.
If the LEAP reporters themselves inadvertently mixed up question 0, question 1, and question 2, it seems pretty likely that a lot of the people answering mixed them up as well.
I think this is made more likely when you look at the actual question on page 104, which is three and a half pages long, because it includes a detailed description of what they mean by “slow”, “medium” and “rapid progress”.[3]. Most of the mental load of the respondents is going to be on digesting these scenarios and comparing them in their head, and there is no reminder at the end as to what the initial question was. I doubt respondents are expecting, when seeing this, to also have to do any analysis on optimal scoring strategy.
I think it’s pretty likely that a lot of people defaulted to answering question 0 or question 1 instead of the actual question, either from misreading the question or through assuming that question 2 was logically equivalent to one of the other two.
In fact, one of the respondents, David Mathers, admitted in an EA forum comment that he made this mistake. David is a smart guy and a superforecaster, it seems unlikely that he was the only one to do so. I might also mention that the authors excluded another question on student AI use from analysis "due to substantial misinterpretation."[4]One group surveyed was the general public, who I would definitely not expect to get this right.
Unfortunately, I think this permanently puts an asterix over the results of this particular question. We don’t know what question the respondents thought they were answering, so we can’t really be sure how to interpret their results.
The response from the team:
In response to this critique, the team went through the document and adjusted the three references to this question to reflect the actual wording. The currently linked version now has been corrected in several places to reflect the actual question asked. For example, the original passage I highlted has been changed to the following:
"By 2030,the average expert thinks that 23% of LEAP panelists will say the state of AI most closely mirrors an (“rapid”) AI progress scenario that matches some of these claims"
I think this is a good step, and I'm always glad to see people willing to correct errors in their work.
I also talked to the team about some of the wider concerns I had. My initial thoughts about this questions were to ask why was the question so complicated in the first place? Why bother with the business of asking what the future LEAP panel will say, rather than just asking question 0? I think they brought up some defensible points in their favour.
Firstly, they want to be able to check the forecasting accuracy of the panel. Part of the research value of making these expert surveys is that we can actually see, long term, how accurate various groups are over time.
Asking people what they believe the future progress will be like is not a question that can be scored objectively. In 2030, there may be disagreement about which scenario actually came to pass. So if we only asked that question, we wouldn’t be able to tell how good experts are at answering these sorts of questions.
I think this is a good point for having some of the questions be scoreable, but non-scoreable questions are still valuable for other reasons (and they do include subjective questions elsewhere). I think this is a case where I really want to know what the experts actual opinion is.
Secondly, they argued that because we trust the panel as a whole more than any individual expert, so shouldn’t we try to forecast the former rather than the latter? Ezra writes in defence of a version of question 1:
“Take a different edge case: if someone (Bob) is a very stubborn person and I know that no matter what happens with AI, Bob will say that the world is closest to the 'rapid' scenario, I (Ezra) still find it useful for Bob to report what his peer experts will say as a group. This separates Bob's views from the expert panel helpfully and in a way that a researcher can reward for accuracy.”
I think this is a reasonable point to consider, but in my opinion, I don’t think you can separate Bob’s view from that of everyone else with just one question.
If someone claims there is a 50% chance that the panel will bring back “rapid”, is that because they think that AI progress is 50% likely to be rapid, and that the panel will be united and answer correctly? Or do they have some other opinion about the actual progress, but they think the panel are monkeys who answer randomly regardless of what actually happens in real life? Both people have wildly different beliefs, but will give the exact same answer to that question.
In theory, you could try to guess their point of view from their other answers, but there aren't that many other questions in each wave, and none of them map 1:1 with this question.
A third defence is that the overall impact of the error is small and should not be characterised as "important". When I described the error as having a large effect on results, Ezra replied:
“… my general frustration with critiques so far on the EA forum is that our long report had five main findings, each of which is supported by multiple pieces of evidence. I don't think your point here, while useful, has any large effects on our results.”
I want to acknowledge that this is a fair point. I do not think that my issues with this one question invalidate the rest of the results, and I don’t want this critique to be interpreted as a takedown of their report as a whole.
I don't really have the time to look over every question in this kind of detail, so I can't say for sure if any of my concerns will transfer to other ones. I notice that there are two other questions that follow this "percentage of LEAP panel" phrasing, although at a glance they seem less confusingly framed. On the other hand, a question like the one on electricity demand seems fairly clear cut and unproblematic.
I don't want to overemphasise the importance of this one question, in the context of a large report, but I don't want to underemphasise it either. Of the 18 questions asked, which you can see on page 94, only a handful [5](2-5,) focus on AI progress in a broad sense, rather than specific benchmarks or milestones. In that sense, it does constitute a key part of the paper, to the point where it was cited twice in the introduction post. I think this was a key question, and it was certainly the one I was most interested in. People want to know if AI will transform the world in the immediate future, and this question was the closest analogue to that.
It is also pretty common for people to pick out individual findings from reports, and I think this is a prime target. I think the ideal solution would be for people to read full reports rather than pulling out of context statistics, but we don't live in an ideal world.
My suggested improvements:
So what should they asked instead? Well, I think they should have asked question 0, for the reasons described above.
I think they should have followed this up with at least one further question.
For example, they could ask a series of questions:
A “What percentage chances do you assign to progress being slow, medium or rapid”?
B “What are the chances that the most common response of the LEAP panel will be slow, medium or rapid”? (you may factor in the chance that they could be wrong).
C If the progress actually is rapid (by your estimation), what percentage of the panel do you think will agree with you and also pick “rapid” when asked in 2030? (repeat for the other three)
Questions B and C can actually be scored, while question A allows us to get a sense of what the expert actually believes. If this is too complicated, then one of B or C could be removed. Having multiple questions allows us to be sure that people are answering the correct question, rather than accidentally conflating them.
In general, I think it is not a good idea to assume that the people answering questions are familiar with forecasting strategy, or even that they are likely to read the question closely.
Conclusion:
I think what I described here is not an easy mistake to spot (I didn't catch it, Yarrow did). It is a good demonstration of how important rigour and review is in good evidence gathering: In this case a small problem with wording ends up putting a major asterix over a key question in the paper. You can also note the disparity between the amount of effort it took to critique these issues with the amount of effort it took to write the questions in the first place.
Hopefully, this analysis will be helpful to future question designers in understanding some of the subtle considerations that need to be considered for future questions of this nature.
You’ll note that 13 and 49 do not add up to 57. They don’t have to, because these are different situations, and the expert here thinks the LEAP panel is slightly biased].


Executive summary: The post argues that a subtle wording error in one LEAP survey question caused respondents and report authors to conflate three distinct questions, making the published statistic unsuitable as evidence about experts’ actual beliefs about future AI progress.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.