The Happier Lives Institute (HLI) is a non-profit research institute that seeks to find the best ways to improve global wellbeing, then share what we find. Established in 2019, we have pioneered the use of subjective wellbeing measures (aka ‘taking happiness seriously’) to work out how to do the most good.
HLI is currently funding constrained and needs to raise a minimum of 205,000 USD to cover operating costs for the next 12 months. We think we could usefully absorb as much as 1,020,000 USD, which would allow us to expand the team, substantially increase our output, and provide a runway of 18 months.
This post is written for donors who might want to support HLI’s work to:
- identify and promote the most cost-effective marginal funding opportunities at improving human happiness.
- support a broader paradigm shift in philanthropy, public policy, and wider society, to put people’s wellbeing, not just their wealth, at the heart of decision-making.
- improve the rigour of analysis in effective altruism and global priorities research more broadly.
A summary of our progress so far:
- Our starting mission was to advocate for taking happiness seriously and see if that changed the priorities for effective altruists. We’re the first organisation to look for the most cost-effective ways to do good, as measured in WELLBYs (Wellbeing-adjusted life years)[1]. We didn’t invent the WELLBY (it’s also used by others e.g. the UK Treasury) but we are the first to apply it to comparing which organisations and interventions do the most good.
- Our focus on subjective wellbeing (SWB) was initially treated with a (understandable!) dose of scepticism. Since then, many of the major actors in effective altruism’s global health and wellbeing space seem to have come around to it (e.g., see these comments by GiveWell, Founders Pledge, Charity Entrepreneurship, GWWC). [Paragraph above edited 10/07/2023 to replace 'all' with 'many' and remove a name (James Snowden) from the list. See below]
- We’ve assessed several top-regarded interventions for the first time in terms of WELLBYs: cash transfers, deworming, psychotherapy, and anti-malaria bednets. We found treating depression is several times more cost-effective than either cash transfers or deworming. We see this as important in itself as well as a proof of concept: taking happiness seriously can reveal new priorities. We've had some pushback on our results, which was extremely valuable. GiveWell’s own analysis concludes treating depression is 2x as good as cash transfers (see here, which includes our response to GiveWell).
- We strive to be maximally philosophically and empirically rigorous. For instance, our meta-analysis of cash transfers has since been published in a top academic journal. We’ve shown how important philosophy is for comparing life-improving against life-extending interventions. We’ve won prizes: our report re-analysing deworming led GiveWell to start their “Change Our Mind” competition. Open Philanthropy awarded us money in their Cause Exporation Prize.
- Our work has an enormous global scope for doing good by influencing philanthropists and public policy-makers to both (1) redirect resources to the top interventions we find and (2) improve prioritisation in general by nudging decision-makers to take a wellbeing approach (leading to resources being spent better, even if not ideally).
- Regarding (1), we estimate that just over the period of Giving Season 2022, we counterfactually moved around $250,000 to our top charity, StrongMinds; this was our first campaign to directly recommend charities to donors[2].
- Regarding (2), the Mental Health Funding Circle started in late 2022 and has now disbursed $1m; we think we had substantial counterfactual impact in causing them to exist. In a recent 80k podcast, GiveWell mention our work has influenced their thinking (GiveWell, by their count, influences $500m a year)[3].
- We’ve published over 25 reports or articles. See our publications page.
- We’ve achieved all this with a small team. Presently, we’re just five (3.5 FTE researchers). We believe we really 'punch above our weight', doing high impact research at a low cost.
- However, we are just getting started. It takes a while to pioneer new research, find new priorities, and bring people around to the ideas. We’ve had some impact already, but really we see that traction as evidence we’re on track to have a substantial impact in the future.
What’s next?
Our vision is a world where everyone lives their happiest life. To get there, we need to work out (a) what the priorities are and (b) have decision-makers in philanthropy and policy-making (and elsewhere) take action. To achieve this, the key pieces are:-
- conducting research to identify different priorities compared to the status quo approaches (both to do good now and make the case)
- developing the WELLBY methodology, which includes ethical issues such as moral uncertainty and comparing quality to quantity of life
- promoting and educating decision-makers on WELLBY monitoring and evaluation
- building the field of academic researchers taking a wellbeing approach, including collecting data on interventions.
Our organisational strategy is built around making progress towards these goals. We've released, today, a new Research Agenda for 2023-4 which covers much of the below in more depth.
In the next six months, we have two priorities:
Build the capacity and professionalism of the team:
- We’re currently recruiting a communications manager. We’re good at producing research, but less good at effectively telling people about it. The comms manager will be crucial to lead the charge for Giving Season this year.
- We’re about to open applications for a Co-Director. They’ll work with me and focus on development and management; these aren’t my comparative advantage and it’ll free me up to do more research and targeted outreach.
- We’re likely to run an open round for board members too.
And, to do more high-impact research, specifically:
- Finding two new top recommended charities. Ideally, at least one will not be in mental health.
- To do this, we’re currently conducting shallow research of several causes (e.g., non-mood related mental health issues, child development effects, fistula repair surgery, and basic housing improvements) with the aim of identifying promising interventions.
- Alongside that, we’re working on wider research agenda, including: an empirical survey to better understand how much we can trust happiness surveys; summarising what we’ve learnt about WELLBY cost-effectiveness so we can share it with others; revise working papers on the nature and measurement of wellbeing; a book review Will MacAskill’s ‘What We Owe The Future’.
The plan for 2024 is to continue developing our work by building the organisation, doing more good research, and then telling people about it. In particular:
- Investigate 4 or 5 more cause areas, with the aim of adding a further three top charities by the end of 2024.
- Develop the WELLBY methodology, exploring, for instance, the social desirability bias in SWB scales
- Explore wider global priorities/philosophical issues, e.g. on the badness of death and longtermism.
- For a wider look at these plans, see our Research Agenda for 2023-4, which we’ve just released.
- If funding permits, we want to grow the team and add three researchers (so we can go faster) and a policy expert (so we can better advocate for WELLBY priorites with governments)
- (maybe) scale up providing technical assistance to NGOs and researchers on how to assess impact in terms of WELLBYs (we do a tiny amount of this now)
- (maybe) launch a ‘Global Wellbeing Fund’ for donors to give to.
- (maybe) explore moving HLI inside a top university.
We need you!
We think we’ve shown we can do excellent, important research and cause outsized impact on a limited budget. We want to thank those who’ve supported us so far. However, our financial position is concerning: we have about 6 months’ reserves and need to raise a minimum of 205,000 USD to cover our operational costs for the next 12 months. This is even though our staff earn about ½ what they would in comparable roles in other organisations. At most, we think we could usefully absorb 1,020,000 USD to cover team expansion to 11 full time employees over the next 18 months.
We hope the problem is that donors believe the “everything good is fully funded” narrative and don’t know that we need them. However, we’re not fully-funded and we do need you! We don’t get funding from the two big institutional donors, Open Philanthropy and the EA Infrastructure fund (the former doesn’t fund research in global health and wellbeing; we didn’t get feedback from the latter). So, we won’t survive, let alone grow, unless new donors come forward and support us now and into the future.
Whether or not you’re interested in supporting us directly, we would like donors to consider funding our recommended charities; we aim to add two more to our list by the end of 2023. We expect these will be able to absorb millions or tens of dollars, and this number will expand as we do more research.
We think that helping us ‘keep the lights on’ for the next 12-24 months represents an unusually large counterfactual opportunity for donors as we expect our funding position to improve. We’ll explore diversifying our funding sources by:
- Seeking support from the wider world of philanthropy (where wellbeing and mental health are increasing popular topics)
- Acquiring conventional academic funding (we can’t access this yet as we’re not UKRI registered, but we’re working on this; we are also in discussions about folding HLI into a university)
- Providing technical consultancy on wellbeing-based monitoring and evaluation of projects (we’re having initial conversations about this too).
To close, we want to emphasise that taking happiness seriously represents a huge opportunity to find better ways to help people and reallocate enormous resources to those things, both in philanthropy and in public-policymaking. We’re the only organisation we know of focusing on finding the best ways to measure and improve the quality of lives. We sit between academia, effective altruism and policy-making, making us well-placed to carry this forward; if we don’t, we don’t know who else will.
If you’re considering funding us, I’d love to speak with you. Please reach out to me at michael@happierlivesinstitute.org and we’ll find time to chat. If you’re in a hurry, you can donate directly here.
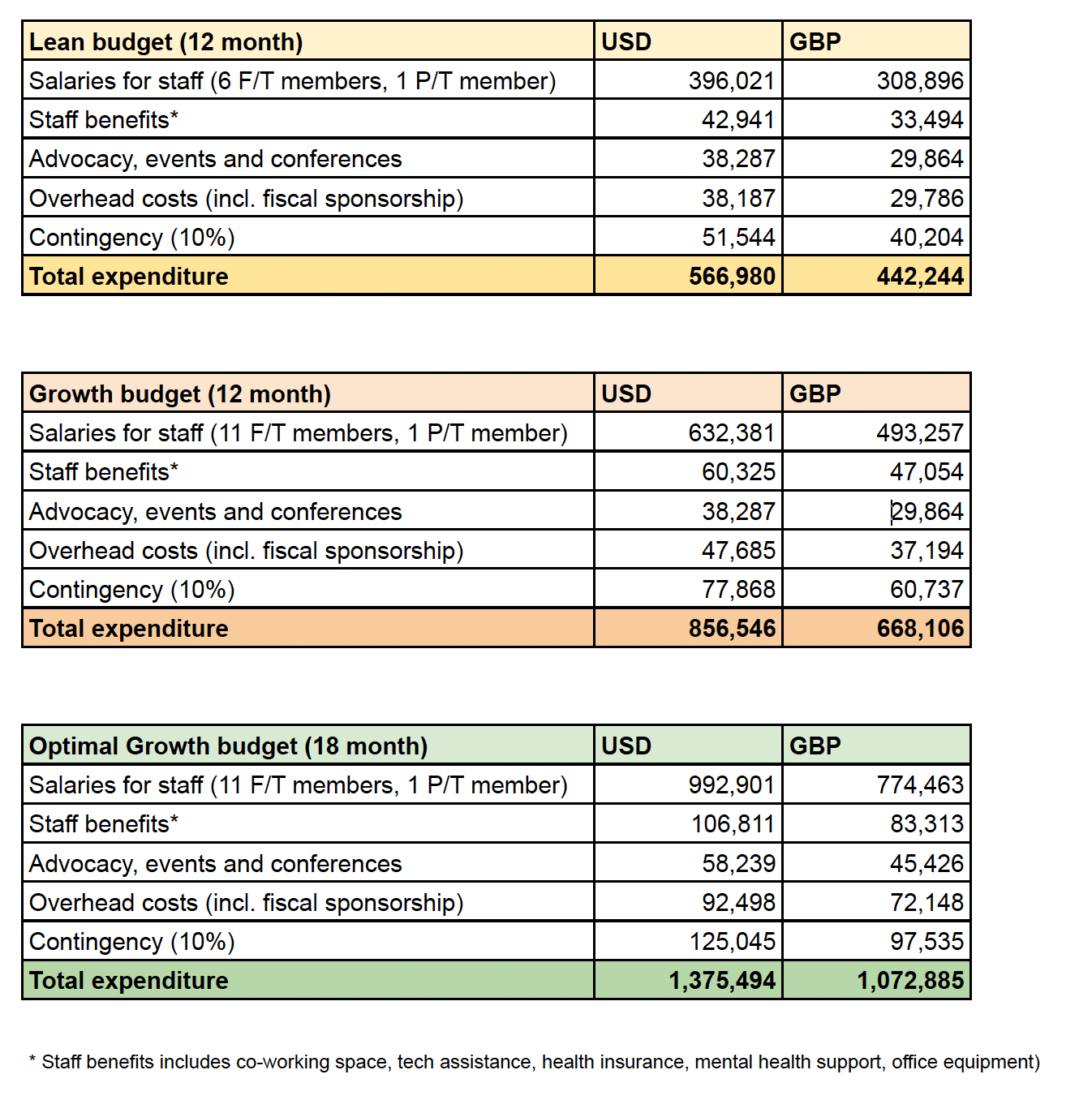
Appendix 1: HLI budget
- ^
One WELLBY is equivalent to a 1-point increase on a 0-10 life satisfaction scale for one year
- ^
The total across two matching campaigns at the Double-Up Drive, the Optimus Foundation as well as donations via three effective giving organisations (Giving What We Can, RC Forward, and Effectiv Spenden) was $447k. Note not all this data is public and some public data is out of date. The sum donated be larger as donations may have come from other sources. We encourage readers to take this with a pinch of salt and how to do more accurate tracking in future.
- ^
Some quotes about HLI’s work from the 80k podcast:
[Elie Hassenfeld] ““I think the pro of subjective wellbeing measures is that it’s one more angle to use to look at the effectiveness of a programme. It seems to me it’s an important one, and I would like us to take it into consideration[Elie] “…I think one of the things that HLI has done effectively is just ensure that this [using WELLBYs and how to make tradeoffs between saving and improving lives] is on people’s minds. I mean, without a doubt their work has caused us to engage with it more than we otherwise might have. […] it’s clearly an important area that we want to learn more about, and I think could eventually be more supportive of in the future.”
[Elie] “Yeah, they went extremely deep on our deworming cost-effectiveness analysis and pointed out an issue that we had glossed over, where the effect of the deworming treatment degrades over time. […] we were really grateful for that critique, and I thought it catalysed us to launch this Change Our Mind Contest. ”


Hello Michael,
Thanks for your reply. In turn:
1:
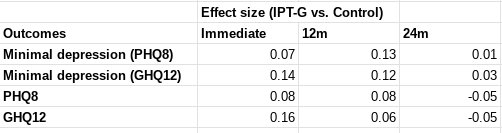
HLI has, in fact, put a lot of weight on the d = 1.72 Strongminds RCT. As table 2 shows, you give a weight of 13% to it - joint highest out of the 5 pieces of direct evidence. As there are ~45 studies in the meta-analytic results, this means this RCT is being given equal or (substantially) greater weight than any other study you include. For similar reasons, the Strongminds phase 2 trial is accorded the third highest weight out of all studies in the analysis.
HLI's analysis explains the rationale behind the weighting of "using an appraisal of its risk of bias and relevance to StrongMinds’ present core programme". Yet table 1A notes the quality of the 2020 RCT is 'unknown' - presumably because Strongminds has "only given the results and some supporting details of the RCT". I don't think it can be reasonable to assign the highest weight to an (as far as I can tell) unpublished, not-peer reviewed, unregistered study conducted by Strongminds on its own effectiveness reporting an astonishing effect size - before it has even been read in full. It should be dramatically downweighted or wholly discounted until then, rather than included at face value with a promise HLI will followup later.
Risk of bias in this field in general is massive: effect sizes commonly melt with improving study quality. Assigning ~40% of a weighted average of effect size to a collection of 5 studies, 4 [actually 3, more later] of which are (marked) outliers in effect effect, of which 2 are conducted by the charity is unreasonable. This can be dramatically demonstrated from HLI's own data:
One thing I didn't notice last time I looked is HLI did code variables on study quality for the included studies, although none of them seem to be used for any of the published analysis. I have some good news, and some very bad news.
The good news is the first such variable I looked at, ActiveControl, is a significant predictor of greater effect size. Studies with better controls report greater effects (roughly 0.6 versus 0.3). This effect is significant (p = 0.03) although small (10% of the variance) and difficult - at least for me - to explain: I would usually expect worse controls to widen the gap between it and the intervention group, not narrow it. In any case, this marker of study quality definitely does not explain away HLI's findings.
The second variable I looked at was 'UnpubOr(pre?)reg'.[1] As far as I can tell, coding 1 means something like 'the study was publicly registered' and 0 means it wasn't (I'm guessing 0.5 means something intermediate like retrospective registration or similar) - in any case, this variable correlates extremely closely (>0.95) to my own coding of whether a study mentions being registered or not after reviewing all of them myself. If so, using it as a moderator makes devastating reading:[2]
To orientate: in 'Model results' the intercept value gives the estimated effect size when the 'unpub' variable is zero (as I understand it, ~unregistered studies), so d ~ 1.4 (!) for this set of studies. The row below gives the change in effect if you move from 'unpub = 0' to 'unpub = 1' (i.e. ~ registered vs. unregistered studies): this drops effect size by 1, so registered studies give effects of ~0.3. In other words, unregistered and registered studies give dramatically different effects: study registration reduces expected effect size by a factor of 3. [!!!]
The other statistics provided deepen the concern. The included studies have a very high level of heterogeneity (~their effect sizes vary much more than they should by chance). Although HLI attempted to explain this variation with various meta-regressions using features of the intervention, follow-up time, etc., these models left the great bulk of the variation unexplained. Although not like-for-like, here a single indicator of study quality provides compelling explanation for why effect sizes differ so much: it explains three-quarters of the initial variation.[3]
This is easily seen in a grouped forest plot - the top group is the non registered studies, the second group the registered ones:
This pattern also perfectly fits the 5 pieces of direct evidence: Bolton 2003 (ES = 1.13), Strongminds RCT (1.72), and Strongminds P2 (1.09) are, as far as I can tell, unregistered. Thurman 2017 (0.09) was registered. Bolton 2007 is also registered, and in fact has an effect size of ~0.5, not 1.79 as HLI reports.[4]
To be clear, I do not think HLI knew of this before I found it out just now. But results like this indicate i) the appraisal of the literature in this analysis gravely off-the-mark - study quality provides the best available explanation for why some trials report dramatically higher effects than others; ii) the result of this oversight is a dramatic over-estimation of likely efficacy of Strongminds (as a ready explanation for the large effects reported in the most 'relevant to strongminds' studies is that these studies were not registered and thus prone to ~200%+ inflation of effect size); iii) this is a very surprising mistake for a diligent and impartial evaluator to make: one would expect careful assessment of study quality - and very sceptical evaluation where this appears to be lacking - to be foremost, especially given the subfield and prior reporting from Strongminds both heavily underline it. This pattern, alas, will prove repetitive.
I also think a finding like this should prompt an urgent withdrawal of both the analysis and recommendation pending further assessment. In honesty, if this doesn't, I'm not sure what ever could.
2:
Indeed excellent researchers overlook things, and although I think both the frequency and severity of things HLI mistakes or overlooks is less-than-excellent, one could easily attribute this to things like 'inexperience', 'trying to do a lot in a hurry', 'limited staff capacity', and so on.
Yet this cannot account for how starkly asymmetric the impact of these mistakes and oversights are. HLI's mistakes are consistently to Strongmind's benefit rather than its detriment, and HLI rarely misses a consideration which could enhance the 'multiple', it frequently misses causes of concern which both undermine both strength and reliability of this recommendation. HLI's award from Givewell deepens my concerns here, as it is consistent with a very selective scepticism: HLI can carefully scruitinize charity evaluations by others it wants to beat, but fails to mete out remotely comparable measure to its own which it intends for triumph.
I think this can also explain how HLI responds to criticism, which I have found by turns concerning and frustrating. HLI makes some splashy claim (cf. 'mission accomplished', 'confident recommendation', etc.). Someone else (eventually) takes a closer look, and finds the surprising splashy claim, rather than basically checking out 'most reasonable ways you slice it', it is highly non-robust, and only follows given HLI slicing it heavily in favour of their bottom line in terms of judgement or analysis - the latter of which often has errors which further favour said bottom line. HLI reliably responds, but the tenor of this response is less 'scientific discourse' and more 'lawyer for defence': where it can, HLI will too often further double down on calls it makes where I aver the typical reasonable spectator would deem at best dubious, and at worst tendentious; where it can't, HLI acknowledges the shortcoming but asserts (again, usually very dubiously) that it isn't that a big deal, so it will deprioritise addressing it versus producing yet more work with the shortcomings familiar to those which came before.
3:
HLI's meta-analysis in no way allays or rebuts the concerns SimonM raised re. Strongminds - indeed, appropriate analysis would enhance many of them. Nor is it the case that the meta-analytic work makes HLI's recommendation robust to shortcomings in the Strongminds-specific evidence - indeed, the cost effectiveness calculator will robustly recommend Strongminds as superior (commonly, several times superior) to GiveDirectly almost no matter what efficacy results (meta-analytic or otherwise) are fed into it. On each.
a) Meta-analysis could help contextualize the problems SimonM identifies in the Strongminds specific data. For example, a funnel plot which is less of a 'funnel' but more of a ski-slope (i.e. massive small study effects/risk of publication bias), and a contour/p-curve suggestive of p-hacking would suggest the field's literature needs to be handled with great care. Finding 'strongminds relevant' studies and direct evidence are marked outliers even relative to this pathological literature should raise alarm given this complements the object-level concerns SimonM presented.
This is indeed true, and these features were present in the studies HLI collected, but HLI failed to recognise it. It may never have if I hadn't gotten curious and did these analyses myself. Said analysis is (relative to the much more elaborate techniques used in HLI's meta-analysis) simple to conduct - my initial 'work' was taking the spreadsheet and plugging it into a webtool out of idle curiosity.[5] Again, this is a significant mistake, adds a directional bias in favour of Strongminds, and is surprising for a diligent and impartial evaluator to make.
b) In general, incorporating meta-analytic results into what is essentially a weighted average alongside direct evidence does not clean either it or the direct evidence of object level shortcomings. If (as here) both are severely compromised, the result remains unreliable.
The particular approach HLI took also doesn't make the finding more robust, as the qualitative bottom line of the cost-effectiveness calculation is insensitive to the meta-analytic result. As-is, the calculator gives strongminds as roughly 12x better than GiveDirectly.[6] If you set both meta-analytic effect sizes to zero, the calculator gives Strongminds as ~7x better than GiveDirectly. So the five pieces of direct evidence are (apparently) sufficient to conclude SM is an extremely effective charity. Obviously this is - and HLI has previously accepted - facially invalid output.
It is not the only example. It is extremely hard for any reduction of efficacy inputs to the model to give a result that Strongminds is worse than Givedirectly. If we instead leave the meta-analytic results as they were but set all the effect sizes of the direct evidence to zero (in essence discounting them entirely - which I think is approximately what should have been done from the start), we get ~5x better than GiveDirectly. If we set all the effect sizes of both meta-analysis and direct evidence to 0.4 (i.e. the expected effects of registered studies noted before), we get ~6x better than Givedirectly. If we set the meta-analytic results to 0.4 and set all the direct evidence to zero we get ~3x GiveDirectly. Only when one sets all the effect sizes to 0.1 - lower than all but ~three of the studies in the meta-analysis - does one approach equipoise.
This result should not surprise on reflection: the CEA's result is roughly proportional to the ~weighted average of input effect sizes, so an initial finding of '10x' Givedirectly or similar would require ~a factor of 10 cut to this average to drag it down to equipoise. Yet this 'feature' should be seen as a bug: in the same way there should be some non-zero value of the meta-analytic results which should reverse a 'many times better than Givedirectly' finding, there should be some non-tiny value of effect sizes for a psychotherapy intervention (or psychotherapy interventions in general) which results in it not being better than GiveDirectly at all.
This does help explain the somewhat surprising coincidence the first charity HLI fully assessed would be one it subsequently announces as the most promising interventions in global health and wellbeing so-far found: rather than a discovery from the data, this finding is largely preordained by how the CEA stacks the deck. To be redundant (and repetitive): i) the cost-effectiveness model HLI is making is unfit-for-purpose, given can produce these absurd results; ii) this introduces a large bias in favour of Strongminds; iii) it is a very surprising mistake for a diligent and impartial evaluator to make - these problems are not hard to find.
They're even easier for HLI to find once they've been alerted to them. I did, months ago, alongside other problems, and suggested the cost-effectiveness analysis and Strongminds recommendation be withdrawn. Although it should have happened then, perhaps if I repeat myself it might happen now.
4:
Accusations of varying types of bad faith/motivated reasoning/intellectual dishonesty should indeed be made with care - besides the difficulty in determination, pragmatic considerations raise the bar still higher. Yet I think the evidence of HLI having less of a finger but more of a fist on the scale throughout its work overwhelms even charitable presumptions made by a saint on its behalf. In footballing terms, I don't think HLI is a player cynically diving to win a penalty, but it is like the manager after the game insisting 'their goal was offside, and my player didn't deserve a red, and.. (etc.)' - highly inaccurate and highly biased. This is a problem when HLI claims itself an impartial referee, especially when it does things akin to awarding fouls every time a particular player gets tackled.
This is even more of a problem precisely because of the complex and interdisciplinary analysis HLI strives to do. No matter the additional analytic arcana, work like this will be largely fermi estimates, with variables being plugged in with little more to inform them than intuitive guesswork. The high degree of complexity provides a vast garden of forking paths available. Although random errors would tend to cancel out, consistent directional bias in model choice, variable selection, and numerical estimates lead to greatly inflated 'bottom lines'.
Although the transparency in (e.g.) data is commendable, the complex analysis also makes scruitiny harder. I expect very few have both the expertise and perseverence to carefully vet HLI analysis themselves; I also expect the vast majority of money HLI has moved has come from those largely taking its results on trust. This trust is ill-placed: HLI's work weathers scruitiny extremely poorly; my experience is very much 'the more you see, the worse it looks'. I doubt many donors following HLI's advice, if they took a peak behind the curtain, would be happy with what they would discover.
If HLI is falling foul of an entrenched status quo, it is not particular presumptions around interventions, nor philosophical abstracta around population ethics, but rather those that work in this community (whether published elsewhere or not) should be even-handed, intellectually honest and trustworthy in all cases; rigorous and reliable commensurate to its expected consequence; and transparently and fairly communicated. I think going against this grain underlies (I suspect) why I am not alone in my concerns, and why HLI has not had the warmest reception. The hope this all changes for the better is not entirely forlorn. But things would have to change a lot, and quickly - and the track record thus far does not spark joy.
Really surprised I missed this last time, to be honest. Especially because it is the only column title in the spreadsheet highlighted in red.
Given I will be making complaints about publication bias, file drawer effects, and garden of forking path issues later in the show, one might wonder how much of this applies to my own criticism. How much time did I spend dredging through HLI's work looking for something juicy? Is my file drawer stuffed with analyses I hoped would show HLI in a bad light, actually showed it in a good one, so I don't mention them?
Depressingly, the answer is 'not much' and 'no' respectively. Regressing against publication registration was the second analysis I did on booting up the data again (regressing on active control was the first, mentioned in text). My file drawer subsequent to this is full of checks and double-checks for alternative (and better for HLI) explanations for the startling result. Specifically, and in order:
- I used the no_FU (no follow-ups) data initially for convenience - the full data can include multiple results of the same study at different follow-up points, and these clustered findings are inappropriate to ignore in a simple random effects model. So I checked both by doing this anyway then using a multi-level model to appropriately manage this structure to the data. No change to the key finding.
- Worried that (somehow) I was messing up or misinterpreting the metaregression, I (re)constructed a simple forest plot of all the studies, and confirmed indeed the unregistered ones were visibly off to the right. I then grouped a forest plot by registration variable to ensure it closely agreed with the meta-regression (in main text). It does.
- I then checked the first 10 studies coded by the variable I think is trial registration to check the registration status of those studies matched the codes. Although all fit, I thought the residual risk I was misunderstanding the variable was unacceptably high for a result significant enough to warrant a retraction demand. So I checked and coded all 46 studies by 'registered or not?' to make sure this agreed with my presumptive interpretation of the variable (in text). It does.
- Adding multiple variables to explain an effect geometrically expands researcher degrees of freedom, thus any unprincipled ad hoc investigation by adding or removing them has very high false discovery rates (I suspect this is a major problem with HLI's own meta-regression work, but compared to everything else it merits only a passing mention here). But I wanted to check if I could find ways (even if unprincipled and ad hoc) to attenuate a result as stark as 'unregistered studies have 3x the registered ones'.
- I first tried to replicate HLI's meta-regression work (exponential transformations and all) to see if the registration effect would be attenuated by intervention variables. Unfortunately, I was unable to replicate HLI's regression results from the information provided (perhaps my fault). In any case, simpler versions I constructed did not give evidence for this.
- I also tried throwing in permutations of IPT-or-not (these studies tend to be unregistered, maybe this is the real cause of the effect?), active control-or-not (given it had a positive effect size, maybe it cancels out registration?) and study Standard Error (a proxy - albeit a controversial one - for study size/precision/quality, so if registration was confounded by it, this slightly challenges interpretation). The worst result across all the variations I tried was to drop the effect size of registration by 20% (~ -1 to -0.8), typically via substitution with SE. Omitted variable bias and multiple comparisons mean any further interpretation would be treacherous, but insofar as it provides further support: adding in more proxies for study quality increases explanatory power, and tends to even greater absolute and relative drops in effect size comparing 'highest' versus 'lowest' quality studies.
That said, the effect size is so dramatic to be essentially immune to file-drawer worries. Even if I had a hundred null results I forgot to mention, this finding would survive a Bonferroni correction.
Obviously 'is the study registered or not'? is a crude indicator of overal quality. Typically, one would expect better measurement (perhaps by including further proxies for underlying study quality) would further increase the explanatory power of this factor. In other words, although these results look really bad, in reality it is likely to be even worse.
HLI's write up on Bolton 2007 links to this paper (I did double check to make sure there wasn't another Bolton et al. 2007 which could have been confused with this - no other match I could find). It has a sample size of 314, not 31 as HLI reports - I presume a data entry error, although it less than reassuring that this erroneous figure is repeated and subsequently discussed in the text as part of the appraisal of the study: one reason given for weighing it so lightly is its 'very small' sample size.
Speaking of erroneous figures, here's the table of results from this study:
I see no way to arrive at an effect size of d = 1.79 from these numbers. The right comparison should surely be the pre-post difference of GIP versus control in the intention to treat analysis. These numbers give a cohen's d ~ 0.5.
I don't think any other reasonable comparison gets much higher numbers, and definitely not > 3x higher numbers - the differences between any of the groups are lower than the standard deviations, so should bound estimates like Cohen's d to < 1.
[Re. file drawer, I guess this counts as a spot check (this is the only study I carefully checked data extraction), but not a random one: I did indeed look at this study in particular because it didn't match the 'only unregistered studies report crazy-high effects' - an ES of 1.79 is ~2x any other registered study.]
Re. my worries of selective scepticism, HLI did apply these methods in their meta-analysis of cash transfers, where no statistical suggestion of publication bias or p-hacking was evident.
This does depend a bit on whether spillover effects are being accounted for. This seems to cut the multiple by ~20%, but doesn't change the qualitative problems with the CEA. Happy to calculate precisely if someone insists.