Claude 3.7's coding ability forced me to reanalyze whether where will be a SWE job for me after college. This has forced me to re-explore AI safety and its arguments, and I have been re-radicalized towards the safety movement.
What I can’t understand, though, is how contradictory so much of Effective Altruism (EA) feels. It hurts my head, and I want to explore my thoughts in this post.
EA seems far too friendly toward AGI labs and feels completely uncalibrated to the actual existential risk (from an EA perspective) and the probability of catastrophe from AGI (p(doom)). Why aren’t we publicly shaming AI researchers every day? Are we too unwilling to be negative in our pursuit of reducing the chance of doom? Why are we friendly with Anthropic? Anthropic actively accelerates the frontier, currently holds the best coding model, and explicitly aims to build AGI—yet somehow, EAs rally behind them? I’m sure almost everyone agrees that Anthropic could contribute to existential risk, so why do they get a pass? Do we think their AGI is less likely to kill everyone than that of other companies? If so, is this just another utilitarian calculus that we accept even if some worlds lead to EA engineers causing doom themselves? What is going on...
I suspect that many in the AI safety community avoid adopting the "AI doomer" label. I also think that many AI safety advocates quietly hope to one day work at Anthropic or other labs and will not publicly denounce a future employer.
Another possibility is that Open Philanthropy (OP) plays a role. Their former CEO now works at Anthropic, and they have personal ties to its co-founder. Given that most of the AI safety community is funded by OP, could there be financial incentives pushing the field more toward research than anti AI-lab advocacy? This is just a suspicion, and I don’t have high confidence in it, but I’m looking for opinions.
Spending time in the EA community does not calibrate me to the urgency of AI doomerism or the necessary actions that should follow. Watching For Humanity’s AI Risk Special documentary made me feel far more emotionally in tune with p(doom) and AGI timelines than engaging with EA spaces ever has. EA feels business as usual when it absolutely should not. More than 700 people attended EAG, most of whom accept X-risk arguments, yet AI protests in San Francisco still draw fewer than 50 people. I bet most of them aren’t even EAs.
What are we doing?
I’m looking for discussion. Please let me know what you think.
I appreciate the concern that you (and clearly many other Forum users) have, and I do empathise. Still, I'd like to present a somewhat different perspective to others here.
I think that this implicitly assumes that there is such a things as "an EA perspective", but I don't think this is a useful abstraction. EA has many different strands, and in general seems a lot more fractured post-FTX.
e.g. You ask "Why aren’t we publicly shaming AI researchers every day?", but if you're an AI-sceptical EA working in GH&D that seems entirely useless to your goals! If you take 'we' to mean all EAs already convinced of AI doom then that's assuming the conclusion, whether there is a action-significant amount of doom is the question here.
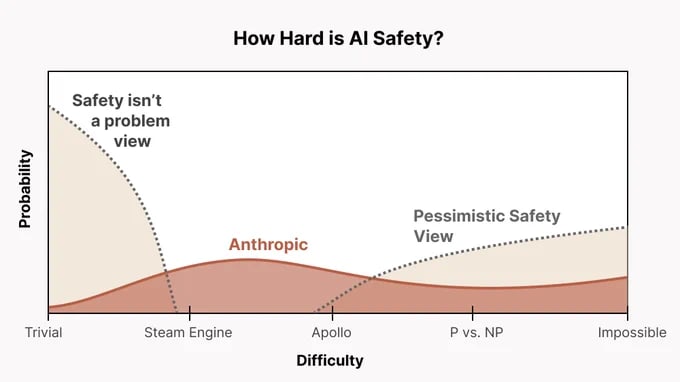
Anthropic's alignment strategy, at least publicly facing, is found here.[1] I think Chris Olah's tweets about it found here include one particularly useful chart:
The probable cruxes here are that 'Anthropic', or various employees there, are much more optimistic about the difficulty of AI safety than you are. They also likely believe that empirical feedback from actual Frontier models is crucial to a successful science of AI Safety. I think if you hold these two beliefs, then working at Anthropic makes a lot more sense from an AI Safety perspective.
For the record, the more technical work I've done, and the more understanding I have about AI systems as they exist today, the more 'alignment optimistic' I've got, and I get increasingly skeptical of OG-MIRI-style alignment work, or AI Safety work done in the absence of actual models. We must have contact with reality to make progress,[2] and I think the AI Safety field cannot update on this point strongly enough. Beren Millidge has really influenced my thinking here, and I'd recommend reading Alignment Needs Empirical Evidence and other blog posts of his to get this perspective (which I suspect many people at anthropic share).
Finally, pushing the frontier of model performance isn't apriori bad, especially if you don't accept MIRI-style arguments. Like, I don't see Sonnet 3.7 as increasing the risk of extinction from AI. In fact, it seems to be both a highly capable model that's also very-well aligned according to Anthropic's HHH criteria. All of my experience using Claude and engaging with the research literature about the model has pushed my distribution of AI Safety towards the 'Steam Engine' level in the chart above, instead of the P vs NP/Impossible level.
Finally, on the 'necessary actions' point, even if we had a clear empirical understanding of what the current p(doom) is, there are no clear necessary actions. There's still lots of arguments to be had here! See Matthew Barnett has argued in these comments that one can make utilitarian arguments for AI acceleration even in the presence of AI risk,[3] or Nora Belrose arguing that pause-style policies will likely be net-negative. You don't have to agree with either of these, but they do mean that there aren't clear 'necessary actions', at least from my PoV.
Of course, if one has completely lost trust with Anthropic as an actor, then this isn't useful information to you at all. But I think that's conceptually a separate problem, because I think have given information to answer the questions you raise, perhaps not to your satisfaction.
Theory will only take you so far
Though this isn't what motivates Anthropic's thinking afaik
To the extent that word captures the classic 'single superintelligent model' form of risk