This is a special post for quick takes by ABishop. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Comment Permalink
Mentioned in
You might be interested in Building Human Values into Recommender Systems: An Interdisciplinary Synthesis as well as Jonathan Stray's other work on alignment and beneficence of recommender systems.
Since around 2017, there has been a lot of public interest in how youtube's recommendation algorithms may affect individuals and society negatively. Governments, think tanks, the press/media, and other institutions have pressured youtube to adjust its recommendations. You could think of this as our world's (indirect & corrupted) way of trying to instill humanity's values into youtube's algorithms.
Haha. Well, I guess I would first ask effective at what? Effective at giving people additional years of healthy & fulfilling life? Effective at creating new friendships? Effective at making people smile?
I haven't studied it at all, but my hypothesis that it is the kind of intervention that is similar to "awareness building," but it doesn't have any call to action (such as a donation). So it is probably effective in giving people a nice experience for a few seconds, and maybe improving their mood for a period of time, but it probably doesn't have longer-lasting effects. From a cursory glance at Google Scholar, it looks like there hasn't been much research on free hugs.
Using the analogy of hunger, here is one way that I am currently thinking about it: giving a willing stranger a hug is like giving a willing stranger a candy bar; they get some nourishment, but if they are chronically food insecure this won't solve that longer-term problem. It won't help them get regular/consistent access to meals that they can afford. So in that sense it is like a band-aid: it is treating the symptom, but it is not addressing the cause.
If someone is suffering from a consistent and pervasive lack of human touch, such as "skinship hunger," a hug might feel nice for a few seconds, but when the hug is finished that person's situation (lacking human touch) remains unchanged. I suppose you could create some kind of program in which they spend 60 minutes with a professional cuddler every week, but I honestly don't see that as being cost competitive if the goal is to get QALYs at the best price.
But if you just want to estimate it then you could put together a simple Fermi estimate: what are the costs to giving free hugs, and what are the benefits, and then figure out how much value do you please on each of those.
It is like a seed. Basic trust and support are provided. It is doubtful whether long-term, indefinite provision is necessary. Wouldn’t it be similar to UBI? I don’t know because there is no research. I believe you are begging the question. I can't agree or disagree with the claim that it will soon return to its initial state without any long-term effects. As for the estimate... I'm not sure. I can't think of a good measure or anything yet. I might need a psychologist to help me. Perhaps an estimate for mental health or well-being, but I doubt QALYs or DALYs. But as an initial estimate, it seems like a good measure. Alternatively, it could be expressed as pain relief or social support. I confess I had no intention of doing any serious research, as I was simply asking for an idea. It's more of a question of whether it's worth it.
Do you believe that altruism actually makes people happy? Peter Singer's book argues that people become happier by behaving altruistically, and psychoanalysis also classifies altruism as a mature defense mechanism. However, there are also concerns about pathological altruism and people pleasers. In-depth research data on this is desperately needed.
Good question I also think about!
After being only for a few months deeply into EA I already realise that discussing with non EA-people makes me emotional, since I "cannot understand" why they are not getting easily convinced of it as well. How can something so logical not being followed by everyone? At least by donating? I think there is the danger to become pathetic if you don't reflect on it and be aware that you cannot convince everybody.
On the other side EA is already having a big impact on how I donate and how I act in my job - so in this regards I do feel much more impactful which certainly makes me happier and more relaxed in other parts of my life as ambitions shifted. Does that make any sense?
Would also be interested on research if anyone has!
Thoughts on project or research auction. It is very cumbersome to apply for funds one by one from Openphil or EA fund. Wouldn't it be better for a major EA organization to auction off the opportunity to participate in a project and let others buy it? It will be similar to a tournament, but you will be able to sell a lot more projects at a lower price and reduce the amount of resources wasted on having many people competing for the same project.
I assume the argument is that neurotic people suffer more when they don't get resources, so resources should go to more neurotic people first?
I think that's correct in an abstract sense but wrong in practice for at least two reasons:
- Utilitarianism says you should work on the biggest problems first. Right now the biggest problems are (roughly) global poverty, farm animal welfare, and x-risk.
- A policy of helping neurotic people encourages people to act more neurotic and even to make themselves more neurotic, which is net negative, and therefore bad according to utilitarianism. Properly-implemented utilitarianism needs to consider incentives.
Curated and popular this week
·
In recent months, the CEOs of leading AI companies have grown increasingly confident about rapid progress:
* OpenAI's Sam Altman: Shifted from saying in November "the rate of progress continues" to declaring in January "we are now confident we know how to build AGI"
* Anthropic's Dario Amodei: Stated in January "I'm more confident than I've ever been that we're close to powerful capabilities... in the next 2-3 years"
* Google DeepMind's Demis Hassabis: Changed from "as soon as 10 years" in autumn to "probably three to five years away" by January.
What explains the shift? Is it just hype? Or could we really have Artificial General Intelligence (AGI) by 2028?[1]
In this article, I look at what's driven recent progress, estimate how far those drivers can continue, and explain why they're likely to continue for at least four more years.
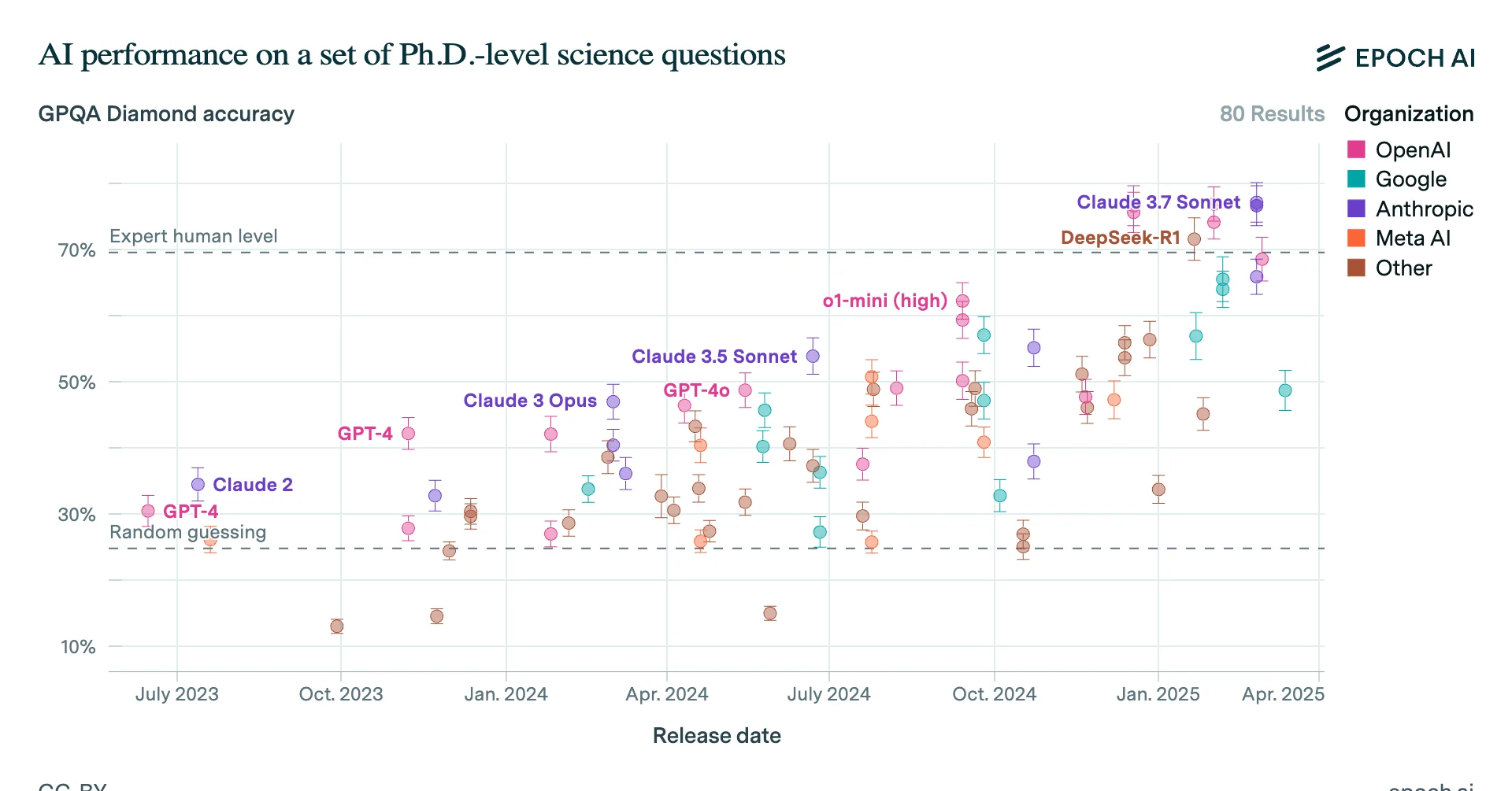
In particular, while in 2024 progress in LLM chatbots seemed to slow, a new approach started to work: teaching the models to reason using reinforcement learning.
In just a year, this let them surpass human PhDs at answering difficult scientific reasoning questions, and achieve expert-level performance on one-hour coding tasks.
We don't know how capable AGI will become, but extrapolating the recent rate of progress suggests that, by 2028, we could reach AI models with beyond-human reasoning abilities, expert-level knowledge in every domain, and that can autonomously complete multi-week projects, and progress would likely continue from there.
On this set of software engineering & computer use tasks, in 2020 AI was only able to do tasks that would typically take a human expert a couple of seconds. By 2024, that had risen to almost an hour. If the trend continues, by 2028 it'll reach several weeks.
No longer mere chatbots, these 'agent' models might soon satisfy many people's definitions of AGI — roughly, AI systems that match human performance at most knowledge work (see definition in footnote).[1]
This means that, while the co
·
Summary
In this article, I estimate the cost-effectiveness of five Anima International programs in Poland: improving cage-free and broiler welfare, blocking new factory farms, banning fur farming, and encouraging retailers to sell more plant-based protein. I estimate that together, these programs help roughly 136 animals—or 32 years of farmed animal life—per dollar spent. Animal years affected per dollar spent was within an order of magnitude for all five evaluated interventions.
I also tried to estimate how much suffering each program alleviates. Using SADs (Suffering-Adjusted Days)—a metric developed by Ambitious Impact (AIM) that accounts for species differences and pain intensity—Anima’s programs appear highly cost-effective, even compared to charities recommended by Animal Charity Evaluators.
However, I also ran a small informal survey to understand how people intuitively weigh different categories of pain defined by the Welfare Footprint Institute. The results suggested that SADs may heavily underweight brief but intense suffering. Based on those findings, I created my own metric DCDE (Disabling Chicken Day Equivalent) with different weightings. Under this approach, interventions focused on humane slaughter look more promising, while cage-free campaigns appear less impactful. These results are highly uncertain but show how sensitive conclusions are to how we value different kinds of suffering.
My estimates are highly speculative, often relying on subjective judgments from Anima International staff regarding factors such as the likelihood of success for various interventions. This introduces potential bias. Another major source of uncertainty is how long the effects of reforms will last if achieved. To address this, I developed a methodology to estimate impact duration for chicken welfare campaigns. However, I’m essentially guessing when it comes to how long the impact of farm-blocking or fur bans might last—there’s just too much uncertainty.
Background
In

·
Crossposted on Substack and Lesswrong.
Introduction
There are many reasons why people fail to land a high-impact role. They might lack the skills, don’t have a polished CV, don’t articulate their thoughts well in applications[1] or interviews, or don't manage their time effectively during work tests. This post is not about these issues. It’s about what I see as the least obvious reason why one might get rejected relatively early in the hiring process, despite having the right skill set and ticking most of the other boxes mentioned above. The reason for this is what I call context, or rather, lack thereof.
Subscribe to The Field Building Blog
On professionals looking for jobs
It’s widely agreed upon that we need more experienced professionals in the community, but we are not doing a good job of accommodating them once they make the difficult and admirable decision to try transitioning to AI Safety.
Let’s paint a basic picture that I understand many experienced professionals are going through, or at least the dozens I talked to at EAGx conferences.
1. They do an AI Safety intro course
2. They decide to pivot their career
3. They start applying for highly selective jobs, including ones at OpenPhilanthropy
4. They get rejected relatively early in the hiring process, including for more junior roles compared to their work experience
5. They don’t get any feedback
6. They are confused as to why and start questioning whether they can contribute to AI Safety
If you find yourself continuously making it to later rounds of the hiring process, I think you will eventually land the job sooner or later. The competition is tight, so please be patient! To a lesser extent, this will apply to roles outside of AI Safety, especially to those aiming to reduce global catastrophic risks.
But for those struggling to penetrate later rounds of the hiring process, I want to suggest a potential consideration. Assuming you already have the right skillset for a given role, it might

Do you believe that altruism actually makes people happy? Peter Singer's book argues that people become happier by behaving altruistically, and psychoanalysis also classifies altruism as a mature defense mechanism. However, there are also concerns about pathological altruism and people pleasers. In-depth research data on this is desperately needed.
Good question I also think about!
After being only for a few months deeply into EA I already realise that discussing with non EA-people makes me emotional, since I "cannot understand" why they are not getting easily convinced of it as well. How can something so logical not being followed by everyone? At least by donating? I think there is the danger to become pathetic if you don't reflect on it and be aware that you cannot convince everybody.
On the other side EA is already having a big impact on how I donate and how I act in my job - so in this ... (read more)