This is a special post for quick takes by bruce. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Comment Permalink
Reposting from LessWrong, for people who might be less active there:[1]
TL;DR
- FrontierMath was funded by OpenAI[2]
- This was not publicly disclosed until December 20th, the date of OpenAI's o3 announcement, including in earlier versions of the arXiv paper where this was eventually made public.
- There was allegedly no active communication about this funding to the mathematicians contributing to the project before December 20th, due to the NDAs Epoch signed, but also no communication after the 20th, once the NDAs had expired.
- OP claims that "I have heard second-hand that OpenAI does have access to exercises and answers and that they use them for validation. I am not aware of an agreement between Epoch AI and OpenAI that prohibits using this dataset for training if they wanted to, and have slight evidence against such an agreement existing."
- Seems to have confirmed the OpenAI funding + NDA restrictions
- Claims OpenAI has "access to a large fraction of FrontierMath problems and solutions, with the exception of a unseen-by-OpenAI hold-out set that enables us to independently verify model capabilities."
- They also have "a verbal agreement that these materials will not be used in model training."
Edit (19/01): Elliot (the project lead) points out that the holdout set does not yet exist (emphasis added):
As for where the o3 score on FM stands: yes I believe OAI has been accurate with their reporting on it, but Epoch can't vouch for it until we independently evaluate the model using the holdout set we are developing.[3]
Edit (24/01):
Tamay tweets an apology (possibly including the timeline drafted by Elliot). It's pretty succinct so I won't summarise it here! Blog post version for people without twitter. Perhaps the most relevant point:
OpenAI commissioned Epoch AI to produce 300 advanced math problems for AI evaluation that form the core of the FrontierMath benchmark. As is typical of commissioned work, OpenAI retains ownership of these questions and has access to the problems and solutions.
Nat from OpenAI with an update from their side:
- We did not use FrontierMath data to guide the development of o1 or o3, at all.
- We didn't train on any FM derived data, any inspired data, or any data targeting FrontierMath in particular
- I'm extremely confident, because we only downloaded frontiermath for our evals *long* after the training data was frozen, and only looked at o3 FrontierMath results after the final announcement checkpoint was already picked .
============
Some quick uncertainties I had:
- What does this mean for OpenAI's 25% score on the benchmark?
- What steps did Epoch take or consider taking to improve transparency between the time they were offered the NDA and the time of signing the NDA?
- What is Epoch's level of confidence that OpenAI will keep to their verbal agreement to not use these materials in model training, both in some technically true sense, and in a broader interpretation of an agreement? (see e.g. bottom paragraph of Ozzi's comment).
- In light of the confirmation that OpenAI not only has access to the problems and solutions but has ownership of them, what steps did Epoch consider before signing the relevant agreement to get something stronger than a verbal agreement that this won't be used in training, now or in the future?
- ^
Epistemic status: quickly summarised + liberally copy pasted with ~0 additional fact checking given Tamay's replies in the comment section
- ^
arXiv v5 (Dec 20th version) "We gratefully acknowledge OpenAI for their support in creating the benchmark."
- ^
See clarification in case you interpreted Tamay's comments (e.g. that OpenAI "do not have access to a separate holdout set that serves as an additional safeguard for independent verification") to mean that the holdout set already exists
Note that the hold-out set doesn't exist yet. https://x.com/ElliotGlazer/status/1880812021966602665
What does this mean for OpenAI's 25% score on the benchmark?
Note that only some of FrontierMath's problems are actually frontier, while others are relatively easier (i.e. IMO level, and Deepmind was already one point from gold on IMO level problems) https://x.com/ElliotGlazer/status/1870235655714025817
Some very quick thoughts from EY's TIME piece from the perspective of someone ~outside of the AI safety work. I have no technical background and don't follow the field closely, so likely to be missing some context and nuance; happy to hear pushback!
Shut down all the large training runs. Put a ceiling on how much computing power anyone is allowed to use in training an AI system, and move it downward over the coming years to compensate for more efficient training algorithms. No exceptions for governments and militaries. Make immediate multinational agreements to prevent the prohibited activities from moving elsewhere. Track all GPUs sold. If intelligence says that a country outside the agreement is building a GPU cluster, be less scared of a shooting conflict between nations than of the moratorium being violated; be willing to destroy a rogue datacenter by airstrike.
Frame nothing as a conflict between national interests, have it clear that anyone talking of arms races is a fool. That we all live or die as one, in this, is not a policy but a fact of nature. Make it explicit in international diplomacy that preventing AI extinction scenarios is considered a priority above preventing a full nuclear exchange, and that allied nuclear countries are willing to run some risk of nuclear exchange if that’s what it takes to reduce the risk of large AI training runs.
- My immediate reaction when reading this was something like "wow, is this representative of AI safety folks? Are they willing to go to any lengths to stop AI development?". I've heard anecdotes of people outside of all this stuff saying this piece reads like a terrorist organisation, for example, which I think is a stronger term than I'd describe, but I think suggestions like this does unfortunately play into potential comparisons to ecofascists.
- As someone seen publicly to be a thought leader and widely regarded as a founder of the field, there are some risks to this kind of messaging. It's hard to evaluate how this trades off, but I definitely know communities and groups that would be pretty put off by this, and it's unclear how much value the sentences around willingness to escalate nuclear war are actually adding.
- It's an empirical Q about how to tradeoff between risks from nuclear war and risks from AI, but the claim of "preventing AI extinction is a priority above a nuclear exchange" is ~trivially true; the reverse is also true: "preventing extinction from nuclear war is a priority above preventing AI training runs". Given the difficulty of illustrating and defending a position that the risks of AI training runs is substantially higher than that of a nuclear exchange to the general public, I would have erred on the side of caution when saying things that are as politically charged as advocating for nuclear escalation (or at least something can be interpreted as such).
- I wonder which superpower EY trusts to properly identify a hypothetical "rogue datacentre" that's worthy of a military strike for the good of humanity, or whether this will just end up with parallels to other failed excursions abroad 'for the greater good' or to advance individual national interests.
- If nuclear weapons are a reasonable comparison, we might expect limitations to end up with a few competing global powers to have access to AI developments, and countries that do not. It seems plausible that criticism around these treaties being used to maintain the status quo in the nuclear nonproliferation / disarmament debate may be applicable here too.
- Unlike nuclear weapons (though nuclear power may weaken this somewhat), developments in AI has the potential to help immensely with development and economic growth.
- Thus the conversation may eventually bump something that looks like:
- Richer countries / first movers that have obtained significant benefits of AI take steps to prevent other countries from catching up.[1]
- Rich countries using the excuse of preventing AI extinction as a guise to further national interests
- Development opportunities from AI for LMICs are similarly hindered, or only allowed in a way that is approved by the first movers in AI.
- Given the above, and that conversations around and tangential to AI risk already receive some pushback from the Global South community for distracting and taking resources away from existing commitments to UN Development Goals, my sense is that folks working in AI governance / policy would likely strongly benefit from scoping out how these developments are affecting Global South stakeholders, and how to get their buy-in for such measures.
(disclaimer: one thing this gestures at is something like - "global health / development efforts can be instrumentally useful towards achieving longtermist goals"[2], which is something I'm clearly interested in as someone working in global health. While it seems rather unlikely that doing so is the best way of achieving longtermist goals on the margin[3], it doesn't exclude some aspect of this in being part of a necessary condition for important wins like an international treaty, if that's what is currently being advocated for. It is also worth mentioning because I think this is likely to be a gap / weakness in existing EA approaches).
Curated and popular this week
·
Confidence: Medium, underlying data is patchy and relies on a good amount of guesswork, data work involved a fair amount of vibecoding.
Intro:
Tom Davidson has an excellent post explaining the compute bottleneck objection to the software-only intelligence explosion.[1] The rough idea is that AI research requires two inputs: cognitive labor and research compute. If these two inputs are gross complements, then even if there is recursive self-improvement in the amount of cognitive labor directed towards AI research, this process will fizzle as you get bottlenecked by the amount of research compute.
The compute bottleneck objection to the software-only intelligence explosion crucially relies on compute and cognitive labor being gross complements; however, this fact is not at all obvious. You might think compute and cognitive labor are gross substitutes because more labor can substitute for a higher quantity of experiments via more careful experimental design or selection of experiments. Or you might indeed think they are gross complements because eventually, ideas need to be tested out in compute-intensive, experimental verification.
Ideally, we could use empirical evidence to get some clarity on whether compute and cognitive labor are gross complements; however, the existing empirical evidence is weak. The main empirical estimate that is discussed in Tom's article is Oberfield and Raval (2014), which estimates the elasticity of substitution (the standard measure of whether goods are complements or substitutes) between capital and labor in manufacturing plants. It is not clear how well we can extrapolate from manufacturing to AI research.
In this article, we will try to remedy this by estimating the elasticity of substitution between research compute and cognitive labor in frontier AI firms.
Model
Baseline CES in Compute
To understand how we estimate the elasticity of substitution, it will be useful to set up a theoretical model of researching better alg

·
This post presents the executive summary from Giving What We Can’s impact evaluation for the 2023–2024 period. At the end of this post we share links to more information, including the full report and working sheet for this evaluation. We look forward to your questions and comments!
This report estimates Giving What We Can’s (GWWC’s) impact over the 2023–2024 period, expressed in terms of our giving multiplier — the donations GWWC caused to go to highly effective charities per dollar we spent. We also estimate various inputs and related metrics, including the lifetime donations of an average 🔸10% pledger, and the current value attributable to GWWC and its partners for an average 🔸10% Pledge and 🔹Trial Pledge.
Our best-guess estimate of GWWC’s giving multiplier for 2023–2024 was 6x, implying that for the average $1 we spent on our operations, we caused $6 of value to go to highly effective charities or funds.
While this is arguably a strong multiplier, readers may wonder why this figure is substantially lower than the giving multiplier estimate in our 2020–2022 evaluation, which was 30x. In short, this mostly reflects slower pledge growth (~40% lower in annualised terms) and increased costs (~2.5x higher in annualised terms) in the 2023–2024 period. The increased costs — and the associated reduction in our giving multiplier — were partly due to one-off costs related to GWWC’s spin-out. They also reflect deliberate investments in growth and the diminishing marginal returns of this spending. We believe the slower pledge growth partly reflects slower growth in the broader effective altruism movement during this period, and in part that GWWC has only started shifting its strategy towards a focus on pledge growth since early 2024. We’ve started seeing some of this pay off in 2024 with about 900 new 🔸10% Pledges compared to about 600 in 2023.
All in all, as we ramp up our new strategy and our investments start to pay off, we aim and expect to sustain a strong (a

·
TLDR: This 6 million dollar Technical Support Unit grant doesn’t seem to fit GiveWell’s ethos and mission, and I don’t think the grant has high expected value.
Disclaimer: Despite my concerns I still think this grant is likely better than 80% of Global Health grants out there. GiveWell are my favourite donor, and given how much thought, research, and passion goes into every grant they give, I’m quite likely to be wrong here!
What makes GiveWell Special?
I love to tell people what makes GiveWell special. I giddily share how they rigorously select the most cost-effective charities with the best evidence-base. GiveWell charities almost certainly save lives at low cost – you can bank on it. There’s almost no other org in the world where you can be pretty sure every few thousand dollars donated be savin’ dem lives.
So GiveWell Gives you certainty – at least as much as possible.
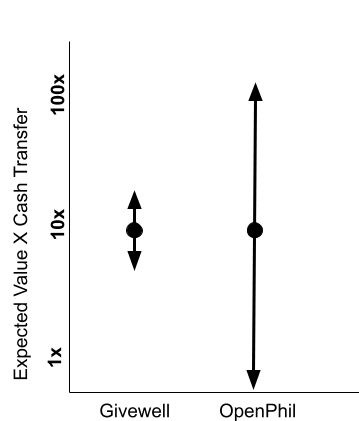
However this grant supports a high-risk intervention with a poor evidence base. There are decent arguments for moonshot grants which try and shift the needle high up in a health system, but this “meta-level”, “weak evidence”, “hits-based” approach feels more Open-Phil than GiveWell[1]. If a friend asks me to justify the last 10 grants GiveWell made based on their mission and process, I’ll grin and gladly explain. I couldn’t explain this one.
Although I prefer GiveWell’s “nearly sure” approach[2], it could be healthy to have two organisations with different roles in the EA global Health ecosystem. GiveWell backing sure things, and OpenPhil making bets.
GiveWell vs. OpenPhil Funding Approach
What is the grant?
The grant is a joint venture with OpenPhil[3] which gives 6 million dollars to two generalist “BINGOs”[4] (CHAI and PATH), to provide technical support to low-income African countries. This might help them shift their health budgets from less effective causes to more effective causes, and find efficient ways to cut costs without losing impact in these leaner times. Teams of 3-5
first funding, then talent, then PR, and now this.
how much juice will OpenAI squeeze out of EA?