Net Promoter Score is a widely used method for determining consumer satisfaction, asking “How likely is it that you would recommend [brand] to a friend or colleague?” and the response is (usually) a number between 0 and 10. However, instead of an average, the aggregate score is a complex nonlinear function of the results. CEA has moved away from this complex function in favor of just simply taking the arithmetic mean. Briefly, this is because the results don’t replicate, NPS is not empirically supported, it requires larger sample sizes, and it violates survey best practices.
Summary
- NPS is widely used, but the research has failed to replicate, even when the replication was using the originally published data set (!).
- Measures of satisfaction are more predictive than NPS of outcomes such as firm growth and whether the respondent actually recommends the product to others.
- The American Customer Satisfaction Index is an alternative which has stronger empirical grounding, as well as a huge number of publicly available benchmarks. It uses 3 questions, on a 10 point scale, whose scores are averaged and normalized to a 0-100 scale:[1]
- What is your overall satisfaction with X?
- To what extent has X met your expectations?
- How well did X compare with the ideal (type of offering)?
- CEA mostly still asks the NPS question, but switched to taking the arithmetic mean of the results. We call this the “likelihood to recommend” (LTR).[2]
More information
- NPS was introduced in 2003 with the claim that it was the best predictor of growth across a data set of companies. This data set was small and subject to p-hacking. The raw data has not been published (including, ironically, the pieces the author says should always be published when reporting NPS scores). The original research methodology was:
“We then obtained a purchase history for each person surveyed and asked those people to name specific instances in which they had referred someone else to the company in question… The data allowed us to determine which survey questions had the strongest statistical correlation with repeat purchases or referrals….
One question was best for most industries. “How likely is it that you would recommend [company X] to a friend or colleague?” ranked first or second in 11 of the 14 cases studies”[3]
- Replication attempts (including ones which reverse engineered the original data set from published scatterplots) have failed to find significant predictive value from NPS. A wide variety of alternative statistical methods exist, some of which have stronger empirical grounding.
- Notably, NPS is worse at predicting whether the respondent will actually recommend the product.
- Replication attempts find alternate definitions of the NPS scale to be more predictive than the commonly used one, even if the question is kept the same (e.g. using a 7 point scale).
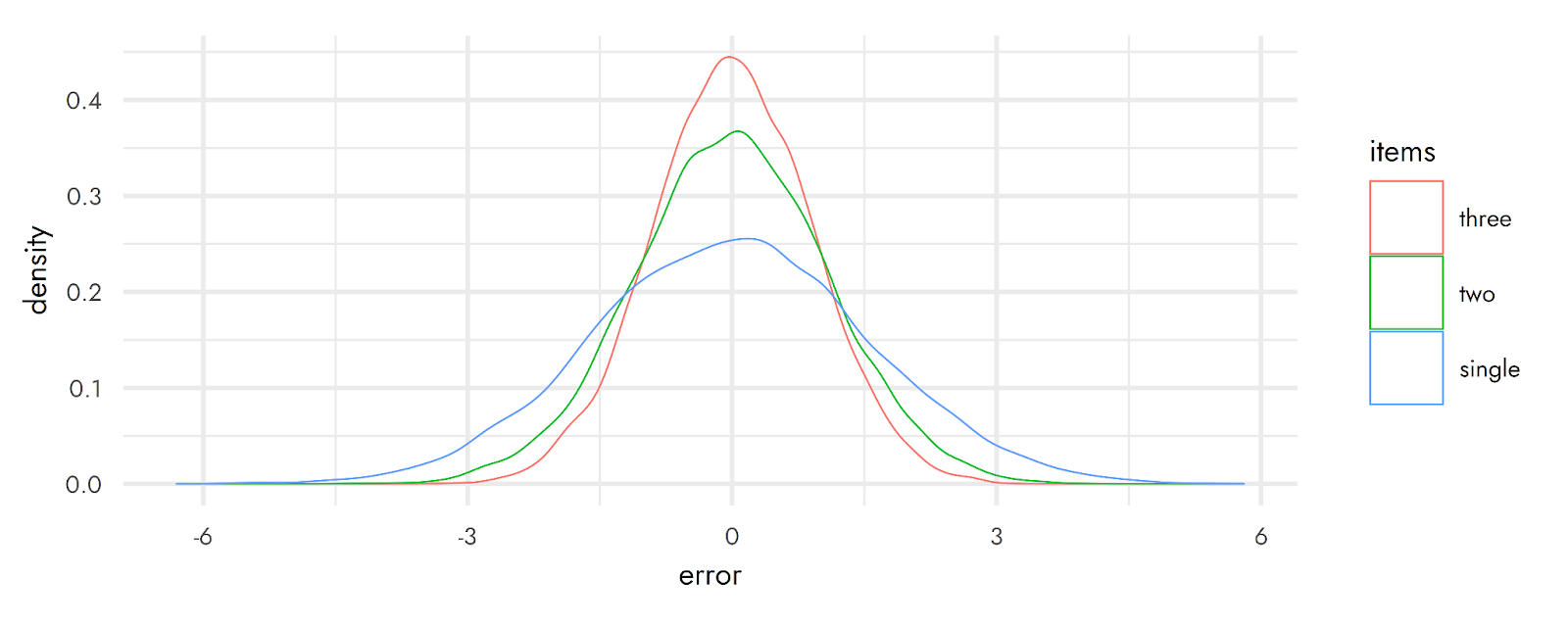
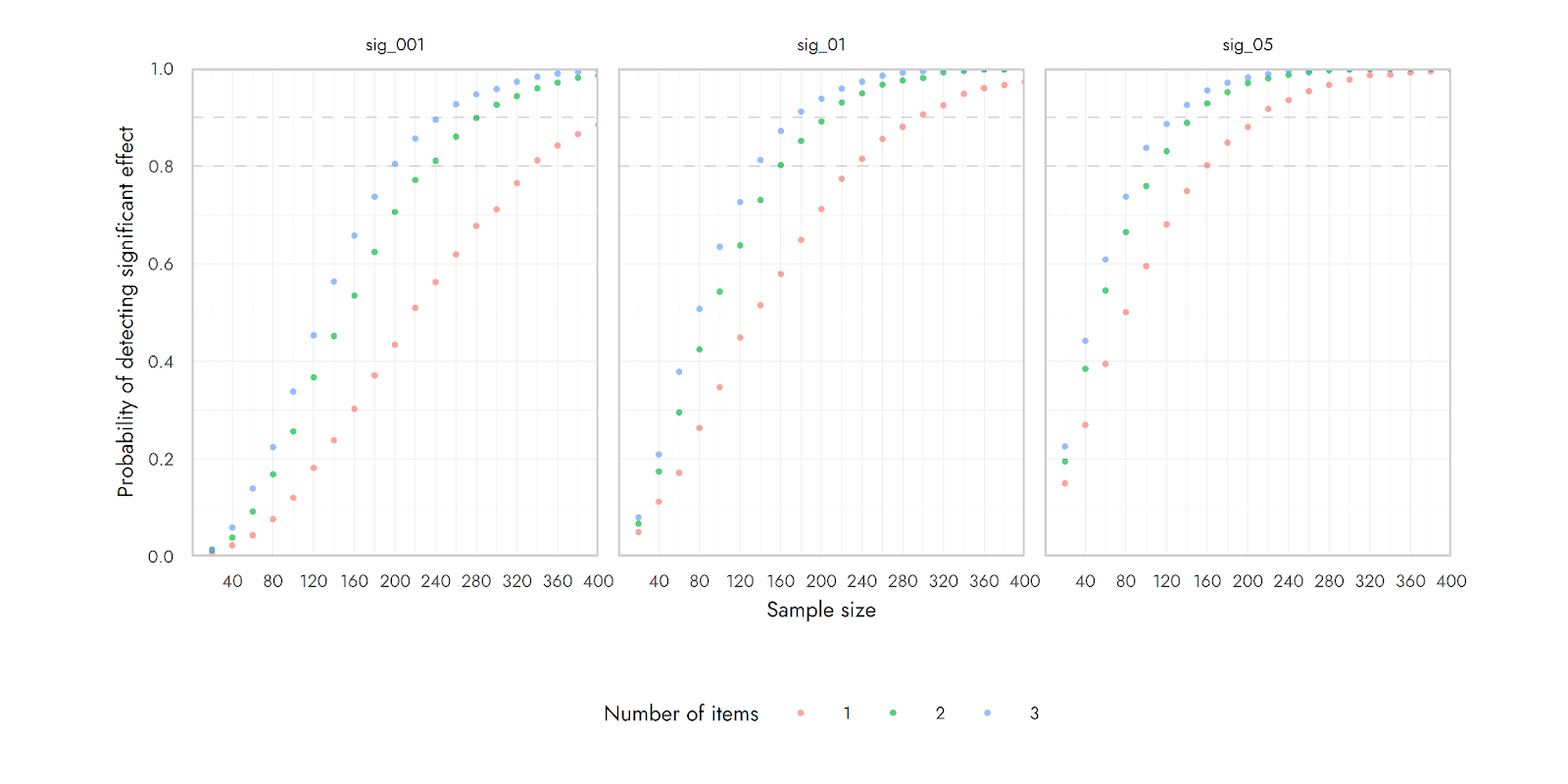
- The weird way NPS is calculated means that it requires substantially larger sample sizes.
- The NPS question disagrees with commonly accepted best practices in survey design (e.g. using an 11-point scale instead of a 5-point one).
- There doesn’t seem to be any particular reason to think that NPS is good, apart from it being widely used.
- So if it’s so terrible, why does everyone use it? This Wall Street Journal article implies that it is used precisely because it’s so easy to manipulate: “Out of all the mentions the Journal tracked on earnings calls, no executive has ever said the score declined.”[4]
Further Reading
- https://www.van-haaften.nl/images/documents/pdf/Measuring%20customer%20satisfaction%20and%20loyalty.pdf
- https://www.researchgate.net/publication/228660597_A_Longitudinal_Examination_of_Net_Promoter_and_Firm_Revenue_Growth
- https://www.researchgate.net/publication/239630908_The_Value_of_Different_Customer_Satisfaction_and_Loyalty_Metrics_in_Predicting_Customer_Retention_Recommendation_and_Share-of-Wallet
- https://community.verint.com/b/customer-engagement/posts/acsi-american-customer-satisfaction-index-score-its-calculation
- https://www.jmir.org/2008/1/e4/
- https://en.wikipedia.org/wiki/American_Customer_Satisfaction_Index
- https://pubsonline.informs.org/doi/10.1287/mksc.1070.0292
- http://www.tsisurveys.com/morgan-rego.pdf
- https://www.van-haaften.nl/images/documents/pdf/Measuring%20customer%20satisfaction%20and%20loyalty.pdf
- ^
- ^
We usually do this because we don’t want to take people’s time up by asking three questions. I haven’t done a very rigorous analysis of the trade-offs here though, and it could be that we are making a mistake and should use ACSI instead.
- ^
“ranked first or second in 11 of the 14 cases studies” should already be setting off alarm bells
- ^
Of course, this doesn’t explain why investors allow executives to tie their compensation to easily hackable metrics.

I'd also be interested in this!