Comments
More from the author
Curated and popular this week
78
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
Adapted from my Substack, Funding Anthropalypse.
Short version: if you want a share of the coming Anthropic and OpenAI windfall - the $37bn+ that could be in play next year - the way in is to become 'legibly excellent', so the evaluators and donors that frontier lab staff already trust point them to yo...

Disclaimer: Although I work on the Groups Team at CEA, I’m writing this in a personal capacity, and this post does not constitute an endorsement by CEA.
Agency - the realisation that you really can just do things.
TL;DR
Biosecurity needs people (of any background) who are agentic and have a high execution velocity and track record....
Recent opportunities to take action
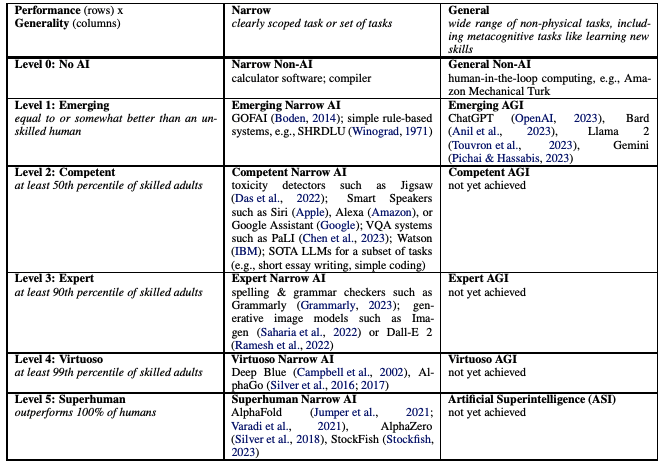
In this "quick take", I want to summarize some my idiosyncratic views on AI risk.
My goal here is to list just a few ideas that cause me to approach the subject differently from how I perceive most other EAs view the topic. These ideas largely push me in the direction of making me more optimistic about AI, and less likely to support heavy regulations on AI.
(Note that I won't spend a lot of time justifying each of these views here. I'm mostly stating these points without lengthy justifications, in case anyone is curious. These ideas can perhaps inform why I spend significant amounts of my time pushing back against AI risk arguments. Not all of these ideas are rare, and some of them may indeed be popular among EAs.)
By comparison, I find it more likely that no individual AI will ever be strong enough to take over the world, in the sense of overthrowing the world's existing institutions and governments by surprise. Instead, I broadly expect unaligned AIs will integrate into society and try to accomplish their goals by advocating for legal rights, rather than trying to overthrow our institutions by force. Upon attaining legal personhood, unaligned AIs can utilize their legal rights to achieve their objectives, for example by getting a job and trading their labor for property, within the already-existing institutions. Because the world is not zero sum, and there are economic benefits to scale and specialization, this argument implies that unaligned AIs may well have a net-positive effect on humans, as they could trade with us, producing value in exchange for our own property and services.
Note that my claim here is not that AIs will never become smarter than humans. One way of seeing how these two claims are distinguished is to compare my scenario to the case of genetically engineered humans. By assumption, if we genetically engineered humans, they would presumably eventually surpass ordinary humans in intelligence (along with social persuasion ability, and ability to deceive etc.). However, by itself, the fact that genetically engineered humans will become smarter than non-engineered humans does not imply that genetically engineered humans would try to overthrow the government. Instead, as in the case of AIs, I expect genetically engineered humans would largely try to work within existing institutions, rather than violently overthrow them.
It is conceivable that GPT-4's apparently ethical nature is fake. Perhaps GPT-4 is lying about its motives to me and in fact desires something completely different than what it professes to care about. Maybe GPT-4 merely "understands" or "predicts" human morality without actually "caring" about human morality. But while these scenarios are logically possible, they seem less plausible to me than the simple alternative explanation that alignment—like many other properties of ML models—generalizes well, in the natural way that you might similarly expect from a human.
Of course, the fact that GPT-4 is easily alignable does not immediately imply that smarter-than-human AIs will be easy to align. However, I think this current evidence is still significant, and aligns well with prior theoretical arguments that alignment would be easy. In particular, I am persuaded by the argument that, because evaluation is usually easier than generation, it should be feasible to accurately evaluate whether a slightly-smarter-than-human AI is taking bad actions, allowing us to shape its rewards during training accordingly. After we've aligned a model that's merely slightly smarter than humans, we can use it to help us align even smarter AIs, and so on, plausibly implying that alignment will scale to indefinitely higher levels of intelligence, without necessarily breaking down at any physically realistic point.
I'm quite skeptical of this argument because I think that the default response to AI (in the absence of intervention from the EA community) will already be quite strong. My view here is informed by the base rate of technologies being overregulated, which I think is quite high. In fact, it is difficult for me to name even a single technology that I think is currently clearly underregulated by society. By pushing for more regulation on AI, I think it's likely that we will overshoot and over-constrain AI relative to the optimal level.
In other words, my personal bias is towards thinking that society will regulate technologies too heavily, rather than too loosely. And I don't see a strong reason to think that AI will be any different from this general historical pattern. This makes me hesitant to push for more regulation on AI, since on my view, the marginal impact of my advocacy would likely be to push us even further in the direction of "too much regulation", overshooting the optimal level by even more than what I'd expect in the absence of my advocacy.
Since unaligned AIs will likely be both conscious and share human social and moral concepts, I don't see much reason to think of them as less "deserving" of life and liberty, from a cosmopolitan moral perspective. They will likely think similarly to the way we do across a variety of relevant axes, even if their neural structures are quite different from our own. As a consequence, I am pretty happy to incorporate unaligned AIs into the legal system and grant them some control of the future, just as I'd be happy to grant some control of the future to human children, even if they don't share my exact values.
Put another way, I view (what I perceive as) the EA attempt to privilege "human values" over "AI values" as being largely arbitrary and baseless, from an impartial moral perspective. There are many humans whose values I vehemently disagree with, but I nonetheless respect their autonomy, and do not wish to deny these humans their legal rights. Likewise, even if I strongly disagreed with the values of an advanced AI, I would still see value in their preferences being satisfied for their own sake, and I would try to respect the AI's autonomy and legal rights. I don't have a lot of faith in the inherent kindness of human nature relative to a "default unaligned" AI alternative.
I think these benefits are large and important, and commensurate with the downside potential of existential risks. While a fully committed strong longtermist might scoff at the idea that curing aging might be important — as it would largely only have short-term effects, rather than long-term effects that reverberate for billions of years — by contrast, I think it's really important to try to improve the lives of people who currently exist. Many people view this perspective as a form of moral partiality that we should discard for being arbitrary. However, I think morality is itself arbitrary: it can be anything we want it to be. And I choose to value currently existing humans, to a substantial (though not overwhelming) degree.
This doesn't mean I'm a fully committed near-termist. I sympathize with many of the intuitions behind longtermism. For example, if curing aging required raising the probability of human extinction by 40 percentage points, or something like that, I don't think I'd do it. But in more realistic scenarios that we are likely to actually encounter, I think it's plausibly a lot better to accelerate AI, rather than delay AI, on current margins. This view simply makes sense to me given the enormously positive effects I expect AI will likely have on the people I currently know and love, if we allow development to continue.
I want to say thank you for holding the pole of these perspectives and keeping them in the dialogue. I think that they are important and it's underappreciated in EA circles how plausible they are.
(I definitely don't agree with everything you have here, but typically my view is somewhere between what you've expressed and what is commonly expressed in x-risk focused spaces. Often also I'm drawn to say "yeah, but ..." -- e.g. I agree that a treacherous turn is not so likely at global scale, but I don't think it's completely out of the question, and given that I think it's worth serious attention safeguarding against.)
Explicit +1 to what Owen is saying here.
(Given that I commented with some counterarguments, I thought I would explicitly note my +1 here.)
This reasoning seems to imply that you could use GPT-2 to oversee GPT-4 by bootstrapping from a chain of models of scales between GPT-2 and GPT-4. However, this isn't true, the weak-to-strong generalization paper finds that this doesn't work and indeed bootstrapping like this doesn't help at all for ChatGPT reward modeling (it helps on chess puzzles and for nothing else they investigate I believe).
I think this sort of bootstrapping argument might work if we could ensure that each model in the chain was sufficiently aligned and capable of reasoning such that it would carefully reason about what humans would want if they were more knowledgeable and then rate outputs based on this. However, I don't think GPT-4 is either aligned enough or capable enough that we see this behavior. And I still think it's unlikely it works under these generous assumptions (though I won't argue for this here).
The obvious example would be synthetic biology, gain-of-function research, and similar.
I also think AI itself is currently massively underregulated even entirely ignoring alignment difficulties. I think the probability of the creation of AI capable of accelerating AI R&D by 10x this year is around 3%. It would be extremely bad for US national interests if such an AI was stolen by foreign actors. This suffices for regulation ensuring very high levels of security IMO. And this is setting aside ongoing IP theft and similar issues.
Can you explain why you suspect these things should be more regulated than they currently are?